搜索到
65
篇与
的结果
-
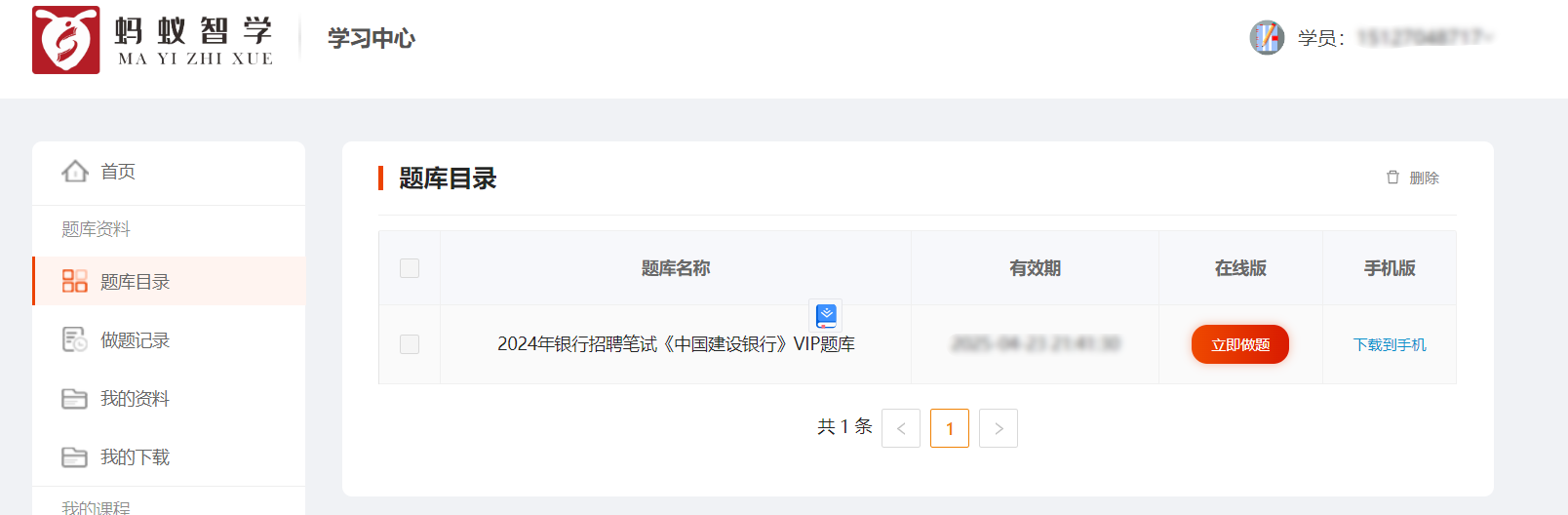
 蚂蚁智学题库爬虫并整理到Excel 接的小私活,目标爬取下来题库并整理到Excel里。目标站点:https://www.mayizhixue.cn/{cloud title="蚂蚁智学" type="bd" url="https://pan.baidu.com/s/1pjg1vTojaazfebpCT1J9SQ?pwd=d2nv" password="d2nv"/}import requests from openpyxl import Workbook from openpyxl.utils import get_column_letter from openpyxl import load_workbook import os common_headers = { 'Authorization': 'TOKEN', } record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows def get_target_row_number(): rows = ws.rows idx = 1 for row in rows: # for cell in row: # print(cell.value, end=' ') # print() if row[0].value is None: return idx idx = idx + 1 return idx def write_row(row, kIndex=None): global record_id rowNumber = get_target_row_number() # print(f"当前行数:{rowNumber}") if kIndex is None: ws.cell(row=rowNumber, column=1).value = record_id else: ws.cell(row=rowNumber, column=1).value = str(record_id) + '.' + str(kIndex) ws.cell(row=rowNumber, column=2).value = row.get('title', '') ws.cell(row=rowNumber, column=3).value = row.get('type', '') # ws.cell(row=rowNumber, column=4).value = row.get('type') # 分数 # ws.cell(row=rowNumber, column=5).value = row.get('type') # 难度 option_idx = 0 for option in row.get('options', []): if 6 + option_idx >= 11: break ws.cell(row=rowNumber, column=6 + option_idx).value = option option_idx = option_idx + 1 ws.cell(row=rowNumber, column=11).value = row.get('answer', '') ws.cell(row=rowNumber, column=12).value = row.get('analysis', '') if kIndex is None: record_id = record_id + 1 def map_type_kv(key): # 1-单选题 2-多选题 6-共享题干题 type = '单选题' if key in ('1', 1): type = '单选题' elif key in ('2', 2): type = '多选题' elif key in ('3', 3): type = '不定项选择题' elif key in ('4', 4): type = '判断题' elif key in ('6', 6): type = '材料题' else: print('不支持的类型:%s' % key) exit() return type def get_test_question(sectionId): params = { 'sectionId': sectionId, 'type': '2', } response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/querySubjectList', params=params, headers=common_headers).json() data = response.get('data') handle_data_2_excel(data) def handle_data_2_excel(data): for i in data: # 此时 i 为对象,取出所有key并遍历 for key in i.keys(): type = map_type_kv(key) # 开始遍历这一题型的所有题目 if type in ['单选题', '多选题', '不定项选择题', '判断题']: for j in i.get(key): row = { 'title': j.get('issue'), 'type': type, 'options': [], 'answer': j.get('answer'), 'analysis': j.get('analysis') } options = j.get('sOption') # 使用|分割选项 options = options.split('|') for k in options: # j为A.选项内容 所以取第三个字符开始 row['options'].append(k[2:]) write_row(row) elif type == '材料题': for j in i.get(key): row = { 'title': j.get('stem'), 'type': type } write_row(row) # 开始爬下面的point kIndex = 1 for k in j.get('childre', []): subtype = map_type_kv(k.get('subType')) row = { 'title': k.get('issue'), 'type': subtype, 'options': [], 'answer': k.get('answer'), 'analysis': k.get('analysis') } options = k.get('sOption') # 使用|分割选项 options = options.split('|') for opt in options: # j为A.选项内容 所以取第三个字符开始 row['options'].append(opt[2:]) write_row(row, kIndex) kIndex = kIndex + 1 def get_exam_question(paperId): response = requests.get( 'https://wx.yiwenjy.cn/yunlian_pc/queryoPaperSubjectList', params={ 'paperId': paperId, 'mode': '2' }, headers=common_headers).json() data = response.get('data') handle_data_2_excel(data) def get_catalogue(courseName, courseId): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/querySectionList', params={ 'courseId': courseId }, headers=common_headers).json() data = response.get('data') for i in data: print(f"当前章节ID:{i.get('id')},章节名称:{i.get('sectionName')}") # 创建相关文件夹 if not os.path.exists(courseName + '/' + i.get('sectionName')): os.makedirs(courseName + '/' + i.get('sectionName')) # 这里需要一直向下判断是否有子节点 copy_i = i # dfs算法 access_next_level(courseName + "/", copy_i) def access_next_level(path, item): global wb, ws, rows, record_id # dfs算法 开始不断找下级 向上返回 if item.get('children') is not None: path = path + item.get('sectionName') + '/' for i in item.get('children'): access_next_level(path, i) else: print(f"当前小节ID:{item.get('id')},小节名称:{item.get('sectionName')}") record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows get_test_question(item.get('id')) # 判断目录是否存在 if not os.path.exists(path): os.makedirs(path) wb.save(f'{path}/{item.get("sectionName")}.xlsx') def get_product_course_info(id): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryProductCourse', params={ 'id': id }, headers=common_headers).json() data = response.get('data') """ 每个ITEM courseName:"中国建设银行VIP" examId:"43d8625d21614cab9f6a2e323e0cd4db" id:"1686999432228376576" """ return data def query_paper_type_list(id): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryPaperTypeList', params={ 'courseId': id }, headers=common_headers).json() """ "id": "1", "paperTypeName": "章节练习", "icon": null, "version": null, "isSection": null, "hasSection": null """ return response.get('data') def get_li_nian_zhen_ti_list(id, paperTypeId): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryPaperList', params={ 'courseId': id, 'paperTypeId': paperTypeId }, headers=common_headers).json() """ 每个ITEM "id": "1703299201187844096", "paperName": "2022年银行招聘笔试《中国建设银行》试题", "onlineTime": "2023-09-17 00:00:00", "referenNumber": 139, "tryBuy": 1, "hasMake": 3, "mode": null """ return response.get('data') course = [ {'id': 'f753f9934c60427fadfba664229a8487', 'name': '2024年军队文职人员招聘《公共科目》题库'} ] for courseItem in course: # 创建科目的文件夹 if not os.path.exists(courseItem.get('name')): os.makedirs(courseItem.get('name')) product_course_info = get_product_course_info(courseItem.get('id')) for product_course in product_course_info: # 查询当前科目下的试卷类型列表 paper_type_list = query_paper_type_list(product_course.get('id')) for paper_type in paper_type_list: print(f"当前科目:{product_course.get('courseName')},当前试卷类型:{paper_type.get('paperTypeName')}") if paper_type.get('paperTypeName') == '章节练习': get_catalogue(courseItem.get("name"), product_course.get('id')) elif paper_type.get('paperTypeName') in ('历年真题', '考前点题', '模拟试卷', '预测试卷', '考前点题'): li_nian_zhen_ti_list = get_li_nian_zhen_ti_list(product_course.get('id'), paper_type.get('id')) for li_nian_zhen_ti in li_nian_zhen_ti_list: record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows print(f"当前试卷ID:{li_nian_zhen_ti.get('id')},试卷名称:{li_nian_zhen_ti.get('paperName')}") get_exam_question(li_nian_zhen_ti.get('id')) wb.save( f'{courseItem.get("name")}/{courseItem.get("name")}-{li_nian_zhen_ti.get("paperName")}.xlsx') else: print("不支持的试卷类型:%s" % paper_type.get('paperTypeName')) exit()
蚂蚁智学题库爬虫并整理到Excel 接的小私活,目标爬取下来题库并整理到Excel里。目标站点:https://www.mayizhixue.cn/{cloud title="蚂蚁智学" type="bd" url="https://pan.baidu.com/s/1pjg1vTojaazfebpCT1J9SQ?pwd=d2nv" password="d2nv"/}import requests from openpyxl import Workbook from openpyxl.utils import get_column_letter from openpyxl import load_workbook import os common_headers = { 'Authorization': 'TOKEN', } record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows def get_target_row_number(): rows = ws.rows idx = 1 for row in rows: # for cell in row: # print(cell.value, end=' ') # print() if row[0].value is None: return idx idx = idx + 1 return idx def write_row(row, kIndex=None): global record_id rowNumber = get_target_row_number() # print(f"当前行数:{rowNumber}") if kIndex is None: ws.cell(row=rowNumber, column=1).value = record_id else: ws.cell(row=rowNumber, column=1).value = str(record_id) + '.' + str(kIndex) ws.cell(row=rowNumber, column=2).value = row.get('title', '') ws.cell(row=rowNumber, column=3).value = row.get('type', '') # ws.cell(row=rowNumber, column=4).value = row.get('type') # 分数 # ws.cell(row=rowNumber, column=5).value = row.get('type') # 难度 option_idx = 0 for option in row.get('options', []): if 6 + option_idx >= 11: break ws.cell(row=rowNumber, column=6 + option_idx).value = option option_idx = option_idx + 1 ws.cell(row=rowNumber, column=11).value = row.get('answer', '') ws.cell(row=rowNumber, column=12).value = row.get('analysis', '') if kIndex is None: record_id = record_id + 1 def map_type_kv(key): # 1-单选题 2-多选题 6-共享题干题 type = '单选题' if key in ('1', 1): type = '单选题' elif key in ('2', 2): type = '多选题' elif key in ('3', 3): type = '不定项选择题' elif key in ('4', 4): type = '判断题' elif key in ('6', 6): type = '材料题' else: print('不支持的类型:%s' % key) exit() return type def get_test_question(sectionId): params = { 'sectionId': sectionId, 'type': '2', } response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/querySubjectList', params=params, headers=common_headers).json() data = response.get('data') handle_data_2_excel(data) def handle_data_2_excel(data): for i in data: # 此时 i 为对象,取出所有key并遍历 for key in i.keys(): type = map_type_kv(key) # 开始遍历这一题型的所有题目 if type in ['单选题', '多选题', '不定项选择题', '判断题']: for j in i.get(key): row = { 'title': j.get('issue'), 'type': type, 'options': [], 'answer': j.get('answer'), 'analysis': j.get('analysis') } options = j.get('sOption') # 使用|分割选项 options = options.split('|') for k in options: # j为A.选项内容 所以取第三个字符开始 row['options'].append(k[2:]) write_row(row) elif type == '材料题': for j in i.get(key): row = { 'title': j.get('stem'), 'type': type } write_row(row) # 开始爬下面的point kIndex = 1 for k in j.get('childre', []): subtype = map_type_kv(k.get('subType')) row = { 'title': k.get('issue'), 'type': subtype, 'options': [], 'answer': k.get('answer'), 'analysis': k.get('analysis') } options = k.get('sOption') # 使用|分割选项 options = options.split('|') for opt in options: # j为A.选项内容 所以取第三个字符开始 row['options'].append(opt[2:]) write_row(row, kIndex) kIndex = kIndex + 1 def get_exam_question(paperId): response = requests.get( 'https://wx.yiwenjy.cn/yunlian_pc/queryoPaperSubjectList', params={ 'paperId': paperId, 'mode': '2' }, headers=common_headers).json() data = response.get('data') handle_data_2_excel(data) def get_catalogue(courseName, courseId): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/querySectionList', params={ 'courseId': courseId }, headers=common_headers).json() data = response.get('data') for i in data: print(f"当前章节ID:{i.get('id')},章节名称:{i.get('sectionName')}") # 创建相关文件夹 if not os.path.exists(courseName + '/' + i.get('sectionName')): os.makedirs(courseName + '/' + i.get('sectionName')) # 这里需要一直向下判断是否有子节点 copy_i = i # dfs算法 access_next_level(courseName + "/", copy_i) def access_next_level(path, item): global wb, ws, rows, record_id # dfs算法 开始不断找下级 向上返回 if item.get('children') is not None: path = path + item.get('sectionName') + '/' for i in item.get('children'): access_next_level(path, i) else: print(f"当前小节ID:{item.get('id')},小节名称:{item.get('sectionName')}") record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows get_test_question(item.get('id')) # 判断目录是否存在 if not os.path.exists(path): os.makedirs(path) wb.save(f'{path}/{item.get("sectionName")}.xlsx') def get_product_course_info(id): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryProductCourse', params={ 'id': id }, headers=common_headers).json() data = response.get('data') """ 每个ITEM courseName:"中国建设银行VIP" examId:"43d8625d21614cab9f6a2e323e0cd4db" id:"1686999432228376576" """ return data def query_paper_type_list(id): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryPaperTypeList', params={ 'courseId': id }, headers=common_headers).json() """ "id": "1", "paperTypeName": "章节练习", "icon": null, "version": null, "isSection": null, "hasSection": null """ return response.get('data') def get_li_nian_zhen_ti_list(id, paperTypeId): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryPaperList', params={ 'courseId': id, 'paperTypeId': paperTypeId }, headers=common_headers).json() """ 每个ITEM "id": "1703299201187844096", "paperName": "2022年银行招聘笔试《中国建设银行》试题", "onlineTime": "2023-09-17 00:00:00", "referenNumber": 139, "tryBuy": 1, "hasMake": 3, "mode": null """ return response.get('data') course = [ {'id': 'f753f9934c60427fadfba664229a8487', 'name': '2024年军队文职人员招聘《公共科目》题库'} ] for courseItem in course: # 创建科目的文件夹 if not os.path.exists(courseItem.get('name')): os.makedirs(courseItem.get('name')) product_course_info = get_product_course_info(courseItem.get('id')) for product_course in product_course_info: # 查询当前科目下的试卷类型列表 paper_type_list = query_paper_type_list(product_course.get('id')) for paper_type in paper_type_list: print(f"当前科目:{product_course.get('courseName')},当前试卷类型:{paper_type.get('paperTypeName')}") if paper_type.get('paperTypeName') == '章节练习': get_catalogue(courseItem.get("name"), product_course.get('id')) elif paper_type.get('paperTypeName') in ('历年真题', '考前点题', '模拟试卷', '预测试卷', '考前点题'): li_nian_zhen_ti_list = get_li_nian_zhen_ti_list(product_course.get('id'), paper_type.get('id')) for li_nian_zhen_ti in li_nian_zhen_ti_list: record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows print(f"当前试卷ID:{li_nian_zhen_ti.get('id')},试卷名称:{li_nian_zhen_ti.get('paperName')}") get_exam_question(li_nian_zhen_ti.get('id')) wb.save( f'{courseItem.get("name")}/{courseItem.get("name")}-{li_nian_zhen_ti.get("paperName")}.xlsx') else: print("不支持的试卷类型:%s" % paper_type.get('paperTypeName')) exit() -
FastAdmin速查手册-常见解决方案 FastAdmin速查手册-常见解决方案忘记密码怎么办?数据库修改fa_admin表的两个字段密码(password):c13f62012fd6a8fdf06b3452a94430e5密码盐(salt):rpR6Bv登录密码是 123456为了你的站点安全,登录后台后请及时修改密码。【分享】忘记 FastAdmin 后台密码了怎么办?:https://ask.fastadmin.net/article/43.html引用1.一张图解析FastAdmin中的表格列表的功能:https://ask.fastadmin.net/article/323.html
-
Discuz X论坛二开速查文档 Discuz X论坛二开速查文档前言公司最近要做一个论坛的小程序,没找到合适的就想用discuz进行二开要购买一套主题,选用themebox的:https://bbs.themebox.cn/portal.php?mobile=2一、数据库操作所有的用户输入数据都建议先使用daddslashes函数处理,以防止SQL注入攻击。1.1 常用API函数功能DB::table($tablename)获取正确带前缀的表名。DB::delete($tablename, 条件,条数限制)删除表中的数据DB::insert($tablename, 数据(数组),是否返回插入ID,是否是替换式,是否silent)插入数据操作DB::update($tablename, 数据(数组)条件)更新操作DB::fetch(查询后的资源)从结果集中取关联数组,注意如果结果中的两个或以上的列具有相同字段名,最后一列将优先。DB::fetch_first($sql)取查询的第一条数据fetchDB::fetch_all($sql)查询并fetchDB::result_first($sql)查询结果集的第一个字段值DB::query($sql)普通查询DB::num_rows(查询后的资源)获得记录集总条数DB::_execute(命令,参数)执行mysql类的命令DB::limit(n,n)返回限制字串DB::field(字段名, $pid)返回条件,如果为数组则返回 in 条件DB::order(别名, 方法)排序注意:由于 X1.5 里增加了SQL的安全性检测。因此,如果你的SQL语句里包含以下开头的函数 load_file,hex,substring,if,ord,char。 或者包含以下操作 intooutfile,intodumpfile,unionselect,(select')都将被拒绝执行。1.2 格式化参数替换参数功能%t表名%s字串,如果是数组就序列化%f按 %F 的样式格式化字串%d整数%i不做处理%n若为空即为0,若为数组,就用',' 分割,否则加引号1.3 C对象方法名参数返回值说明C::t($tablename)->insert()数据数组新插入记录的 ID 或影响行数插入一条新记录到数据表C::t($tablename)->update()条件,更新数据影响行数根据条件更新记录C::t($tablename)->delete()条件影响行数根据条件删除记录C::t($tablename)->fetch()条件单条记录的数组根据条件获取一条记录C::t($tablename)->fetch_all()条件所有符合条件的记录的数组根据条件获取多条记录C::t($tablename)->count()条件记录数根据条件统计记录数C::t($tablename)->truncate() 清空表C::t($tablename)->fetch_all_field() fetch所有的字段名C::t($tablename)->optimize() 优化表二、Discuz源码结构DISCUZ使用自己的框架,与现在主流的web框架不同,DISCUZ没有路由表,他的路由是由入口文件来实现的。2.1 目录讲解api: Discuz 论坛和其他系统的接口文件文件名功能uc.phpUCenter 通信文件/api/addons应用中心/api/connect通讯互联/api/googleGoogle引擎结构处理/api/javascript数据和广告的js调用/api/manyoumanyou应用及搜索等相关服务/api/remote远程更新/api/trade支付宝、财付通等交易接口archiver: 论坛Archiver静态化目录 config: 论坛配置文件目录文件名功能config_global.php论坛核心参数配置文件config_ucenter.phpUCenter核心参数配置文件data: 论坛数据缓存目录文件名功能install论坛安装目录source程序后端功能处理目录discuz_version.php程序版本号文件source: 程序核心目录文件名功能/source/admincp后台管理/source/archiver论坛archiver静态化程序目录/source/class核心类库/source/functiondiscuzX自定义函数库/source/include程序功能组件目录/source/language程序语言包(kv结构)/source/module程序功能模块程序包/source/plugin插件扩展目录static: 程序资源目录(头像、图片、下载文件、js文件等等)template:前端模板目录文件名功能/default/common基础css文件、header、footer等公共引入文件/default/collage大学计划页面/default/digedige专区页面/default/forum首页、帖子页面/default/member会员页面/default/home家园页面/default/group群组页面/default/mobile移动端页面/default/portal文章页面/default/search搜索页面uc_client: UCenter客户端目录文件名功能/uc_client/controlUC业务处理操作类/uc_client/data缓存文件目录/uc_client/lib类库目录(包括数据库操作类,XML类,UCCODE类,邮件发送类)/uc_client/modelUC业务模型类uc_serverUCenter服务端 后台ucenter功能实现目录根目录文件文件名功能admin.php后台入口文件api.phpAPI输出 入口文件connect.php云平台接口文件forum.php帖子信息入口文件group.php群组入口文件home.php家园入口文件index.php首页member.php用户入口文件(登录、注册、退出等)misc.php程序杂项扩展入口plugin.php插件入口文件portal.php门户入口文件robots.txt搜索引擎限制文件search.php搜索频道入口文件2.2 运行逻辑discuz的入口文件起到了路由的作用。一个标准的discuz请求如下:http://localhost/home.php?mod=space&uid=1&do=profile三、广告3.1、获取自定义广告下的所有item这里自定义的广告位于pre_common_advertisement_custom要查某一个类型下的所有文章可以通过名字来获取到id// 1.首先查询pre_common_advertisement_custom表获取name为小程序的id $adid = DB::result_first("SELECT id FROM " . DB::table('common_advertisement_custom') . " WHERE name = '小程序'");再根据id查询pre_common_advertisement表,关联字段位于parameters字段,需要拼接判断// 2.查询pre_common_advertisement表获取广告信息 $flag = ':"' . $adid . '";}s:'; $ad = DB::fetch_all("SELECT parameters FROM " . DB::table('common_advertisement') . " WHERE available = '1' AND parameters LIKE '%$flag%'"); $adresult = []; // 3.将所有的code存入数组 foreach ($ad as $key => $value) { $unse = unserialize($value['parameters']); $adresult[] = [ 'link' => $unse['link'], 'url' => $unse['url'] ]; }序列化的内容为:array(9) { ["extra"]=> array(1) { ["customid"]=> string(1) "1" } ["style"]=> string(5) "image" ["link"]=> string(9) "baidu.com" ["alt"]=> string(0) "" ["width"]=> string(0) "" ["height"]=> string(0) "" ["url"]=> string(67) "https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png" ["html"]=> string(130) "" ["displayorder"]=> string(0) "" }引用1.主题盒子官网:https://www.themebox.cn/2.主题盒子Themebox演示站:https://bbs.themebox.cn/portal.php?mobile=23.黄聪:Discuz!X/数据库操作方法、DB::table、C::t :https://www.cnblogs.com/huangcong/p/4080179.html4.全栈程序员站长:https://cloud.tencent.com/developer/user/8223537
-
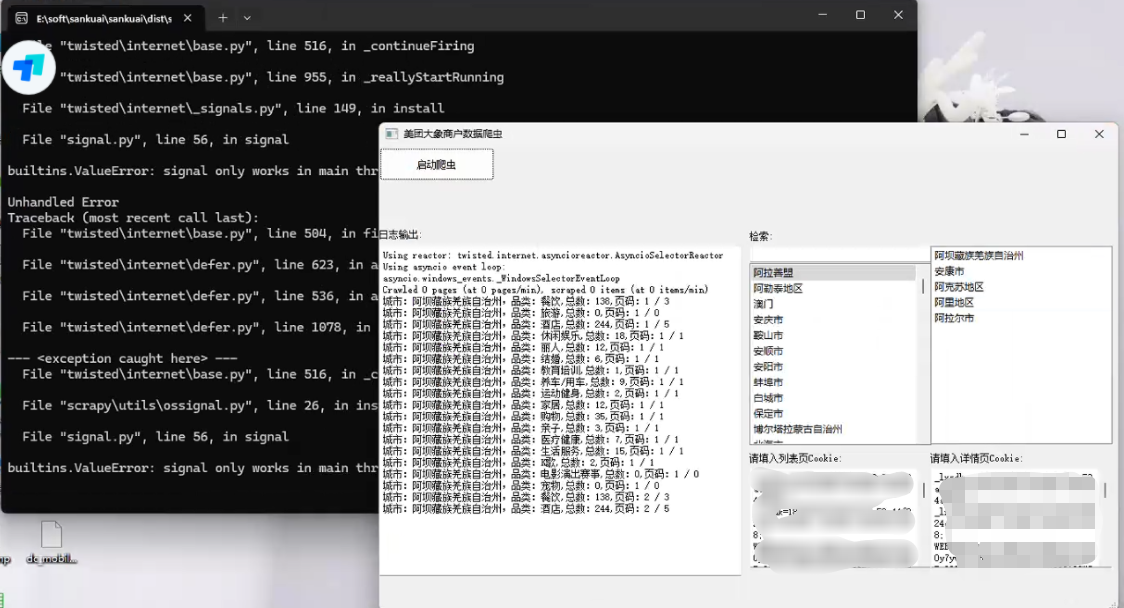
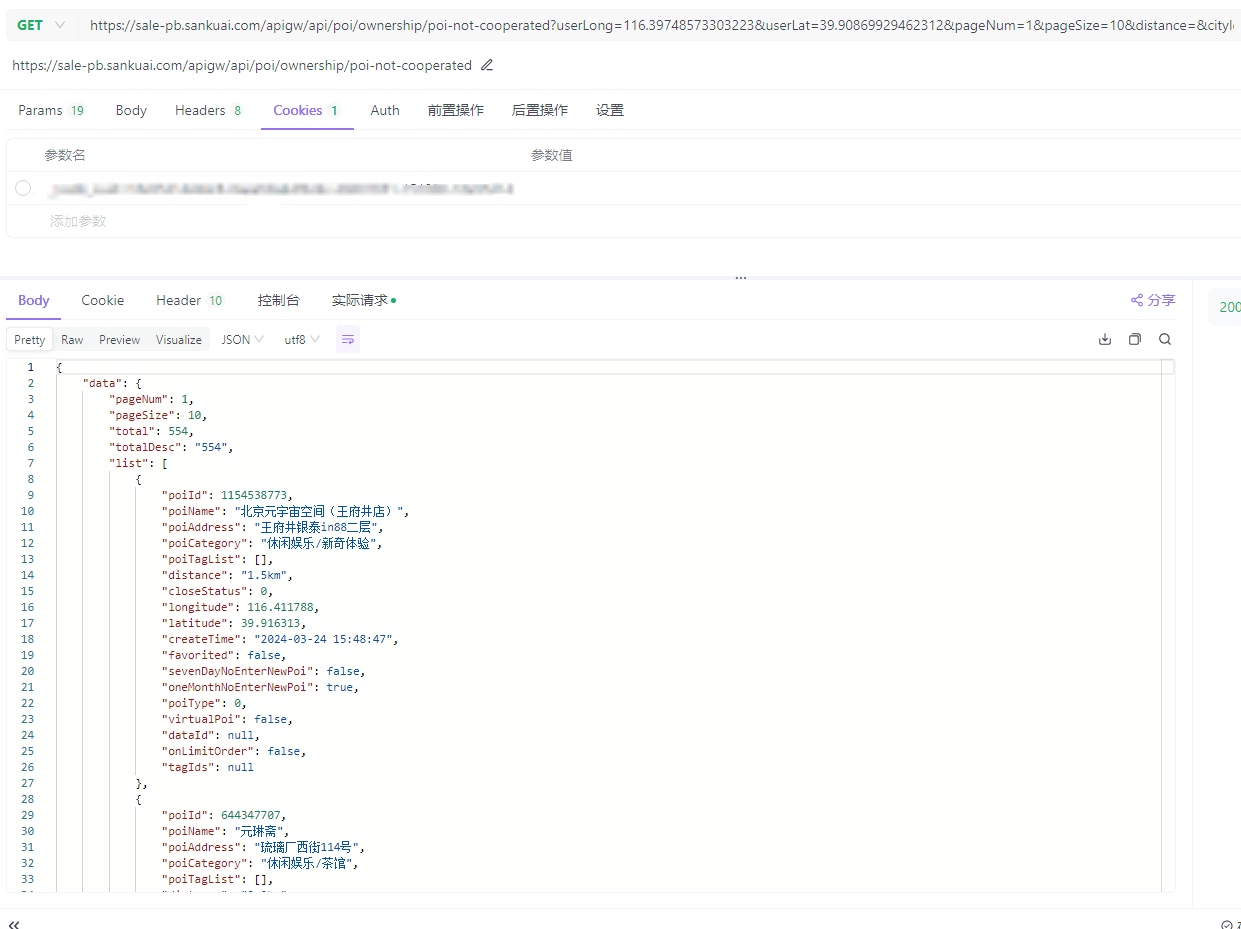
美团旗下大象商户数据爬虫2-为爬虫绘制GUI并打包 前言公司最近的业务,继上文:https://lisok.cn/python/552.htmlcmd命令的使用有点麻烦,于是学习了一下PyQt5画了一个GUI实现有几个点需要提一下这里的日志输出是给logging添加了拦截器日志内容分成两部分如图,其中store记录的是自己代码中打印的,scrapy.utils.log是scrapy内部记录的一些日志统一添加一个handler处理 回调显示在界面上。store.pyfrom ui.mainwindow import signal class MyCustomHandler(logging.Handler): def __init__(self, signals): super(MyCustomHandler, self).__init__() self.signals = signals def emit(self, record): log_message = self.format(record) # 发送消息到 PyQt 界面 self.signals.log_signal.emit(log_message) class StoreSpider(scrapy.Spider): name = "store" allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com'] start_urls = ["https://sale-pb.sankuai.com/apigw/api/poi/ownership/poi-not-cooperated"] baseinfo_url = 'https://crm.sankuai.com/poi/sales/report/baseinfo?shopId={}' pageSize = 60 pageNum = 1 startCategoryId = 0 startRequest = True infoHeaders = {"Content-Type": "application/json; charset=UTF-8"} custom_settings = { 'LOG_LEVEL': 'INFO', 'LOG_FILE': 'sankuai-cus.log', } def __init__(self, *args, **kwargs): log_names = ['store', 'scrapy.utils.log', 'scrapy.extensions.logstats'] # 'scrapy.addons', 'scrapy.extensions.telnet', 'scrapy.middleware', # 'scrapy.crawler', 'scrapy.core.engine', for log_name in log_names: logging.getLogger(log_name).addHandler(MyCustomHandler(signal)) super().__init__(*args, **kwargs) # 设置Cookie self.cookies = kwargs.get('cookies', []) self.crawl_cities_ids = kwargs.get('crawl_cities_ids', []) # ....mainwindow.pyfrom PyQt5.QtCore import QThread, pyqtSignal, QObject from .ui_main_window.ui_mainwindow import Ui_MainWindow cities = [] class MySignal(QObject): log_signal = pyqtSignal(str) signal = MySignal() cookies = [] crawl_cities_ids = [] # ...其他的代码都很常规,打个包记录一下{cloud title="美团-大象商户爬虫.zip" type="bd" url="/我的分享/美团-大象商户爬虫.zip" password=""/}引用1.python scrapy框架 日志文件:https://blog.csdn.net/weixin_45459224/article/details/1001425372.[Python自学] PyQT5-子线程更新UI数据、信号槽自动绑定、lambda传参、partial传参、覆盖槽函数:https://www.cnblogs.com/leokale-zz/p/13131953.html3.[ PyQt入门教程 ] PyQt5中多线程模块QThread使用方法:https://www.cnblogs.com/linyfeng/p/12239856.html4.Scrapy Logging:https://docs.scrapy.org/en/latest/topics/logging.html#logging-configuration5.在线程中启动scrapy以及多次启动scrapy报错的解决方案(ERROR:root:signal only works in main thread):https://blog.csdn.net/Pual_wang/article/details/106466017
-
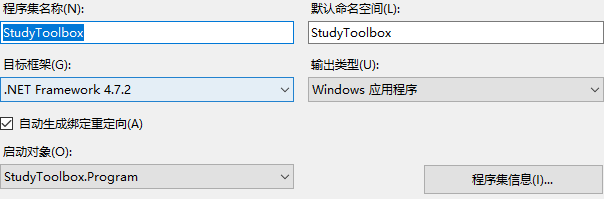
Winform基于.Net Framework4.7.2 启动宿主Web服务 前言编写的客户端需要启动WEB服务,接受其他项目的回调项目使用的框架版本:.NET Framework 4.7.2步骤一、引入依赖Microsoft.AspNet.WebApi.ClientMicrosoft.AspNet.WebApi.SelfHost二、编写HttpServer.cs,作为HTTP服务的启动类using System.Threading.Tasks; using System.Web.Http; using System.Web.Http.SelfHost; namespace StudyToolbox { public class HttpServer { private HttpSelfHostServer server; public HttpServer(string ip, int port) { var config = new HttpSelfHostConfiguration($"http://{ip}:{port}"); //创建宿主服务 config.MapHttpAttributeRoutes(); //添加路由属性 config.Routes.MapHttpRoute("DefaultApi", "api/{controller}/{action}"); //指定路由规则 // 默认首页路由 config.Routes.MapHttpRoute(name: "Root", routeTemplate: "", defaults: new { controller = "Home", action = "Index" }); server = new HttpSelfHostServer(config); } /// <summary> /// 开启服务(异步任务方式) /// </summary> /// <returns></returns> public Task StartHttpServer() { return server.OpenAsync(); } /// <summary> /// 关闭服务(异步任务方式) /// </summary> /// <returns></returns> public Task CloseHttpServer() { return server.CloseAsync(); } } }三、编写控制器using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Web.Http; namespace StudyToolbox.Web.Controller { public class HomeController:ApiController { [HttpGet] public IHttpActionResult Index() { return Json("成功接入StudyToolbox的服务端页面"); } [HttpGet] public IHttpActionResult HelloWork() { return Json("xxx"); } } } 四、访问引用1.Winform窗体利用WebApi接口实现ModbusTCP数据服务:https://blog.csdn.net/hqwest/article/details/130797598
-
美团旗下大象商户数据爬虫1-Python将Scrapy程序打包成exe 本文开发环境:Python3.9前言最近公司有业务开展到爬美团下 大象的商户信息# 主要是这两个域名 allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com']Pycharm在开发机器上采集占用太高了,于是想打包成exe部署到服务器上跑环境配置包配置:包名版本Scrapy2.11.1pyinstaller6.5.0 步骤一、编写程序入口参考官方文档:https://doc.scrapy.org/en/latest/topics/practices.htmlsankuai/run.pyfrom scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings # 下面的包是项目中用到的包,根据自己的项目自行添加,也可以根据打包运行的报错信息,逐个添加 import js2xml import os settings = get_project_settings() process = CrawlerProcess(settings) process.crawl('store') # 填入你需要运行的文件名 process.start()二、数据保存本来是想用FEED来保存数据,可以通过控制台来控制保存地址sankuai/run.pysettings = get_project_settings() settings.setdict({ 'FEED_FORMAT': 'csv', 'FEED_URI': os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data.csv') }, priority="project") process = CrawlerProcess(settings)但是测试发现只会创建文件,并不会写入数据,这里没有解决 有后续了再贴替代方案使用pipeline.pysankuai/sankuai/pipeline.pyclass SankuaiPipeline: def __init__(self): # data文件夹不存在则创建 if not os.path.exists('./data'): os.mkdir('./data') def process_item(self, item, spider): with open('./data/' + item.get('cityName') + '.csv', 'a+', encoding='gbk', newline='') as f: writer = csv.writer(f) writer.writerow((item.get('cityName'), item.get('phone'), item.get('phone2'))) return item sankuai/sankuai/settings.py# ... # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { "sankuai.pipelines.SankuaiPipeline": 300, } # ...三、打包打包执行命令:pyinstaller.exe .\run.py打包后的文件会位于sankuai/dist/run/run.exe,通过cmd运行项目中读取的文件需要放到同一个运行目录中,我这里是category.json和city.json还有两个Cookie文件四、运行出现KeyError: 'Spider not found:爬虫名,可以将项目源码和打包程序放在一块,即打包时生成时的目录结构,不要改变,拷贝时连同项目整体拷贝,亲测有效。打包时直接将sankuai目录压缩了,不然会出现其他问题,当然安全性没有保障(源码都泄露出去了)公司自用就无所谓了引用1.python 将Scrapy项目打包成exe及注意事项 :https://www.cnblogs.com/zhengxianfa/p/16767965.html2.【scrapy打包】使用pyinstaller将scrapy项目打包成独立可执行exe,及可能遇到的问题和解决方法:https://blog.csdn.net/qq_51543898/article/details/1368468103.The application can not locate Python39.dll (126)找不到指定的模块。解决方法:https://blog.csdn.net/wushaoqiu2011/article/details/1101824974.用Pyinstaller打包Scrapy项目问题解决!!!:https://pyqt5.blog.csdn.net/article/details/79017358
-
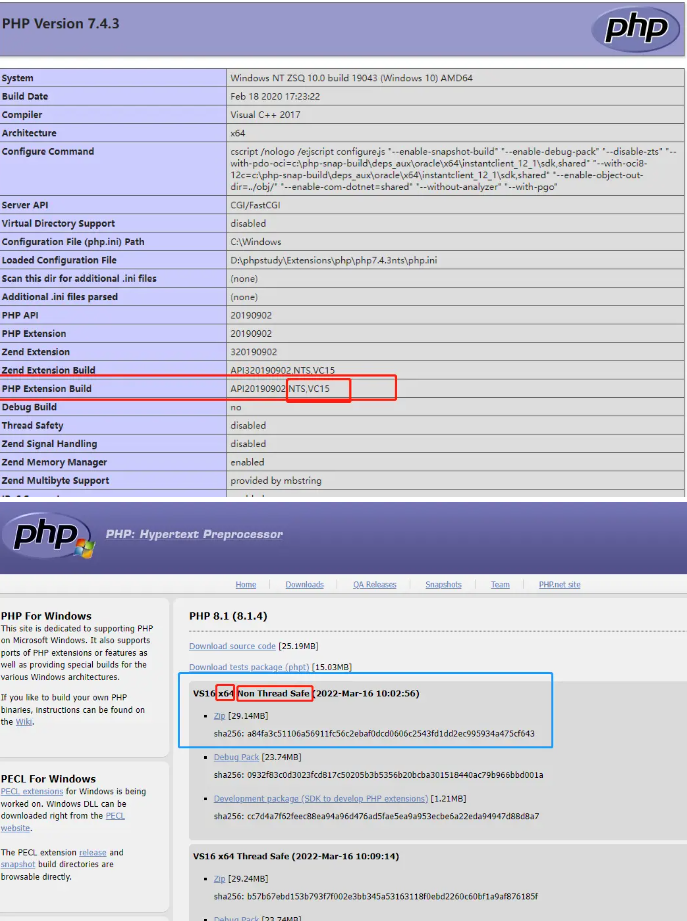
PHPStudy自己扩展php8.1等其他版本 首先需要下载php8.1https://windows.php.net/download#php-8.1php8.1下载地址根据自己的电脑情况选择 32位还是64位的点击下载即可,下载完成后需要找到安装phpstudy的位置找到了放php版本的目录就好了然后在下载下来的文件放入即可 可根据上面文件夹名字适当修改保持队形放置好后可以查看一下 创建的网站也能使用php8.1版本了这样就ok了 。设置好后 需要把文件夹中的配置文件复制一下修改一下名称修改配置项ext前,先将extension_dir = "ext"解开注释这样就可以在phpstudy中直接打开配置文件了引用1.https://www.kancloud.cn/zsq1104/php_study/1730384
-
Git 之 提交代码时的默认提交规则标签简单说明整理 feat/fix/doc/styles/revert/test/build等 Git 之 提交代码时的默认提交规则标签简单说明整理 feat/fix/doc/styles/revert/test/build等一、简单介绍Git(读音为/gɪt/。)是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。 [1] Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。本节介绍,Git 之 reset --hard 回退/回滚到之前的版本代码后,可能又由于冲动,可能需要恢复回退/回滚版本,这里简单整理回退的方法,如果有不足之处,欢迎指出,或者你有更好的方法,欢迎留言。二、常用的代码提交默认前缀标签规则1、feat: 新功能(feature)2、fix: 修补bug3、docs: 文档(documentation)4、style: 格式(不影响代码运行的变动)5、refactor: 重构(即不是新增功能,也不是修改bug的代码变动)6、chore: 构建过程或辅助工具的变动7、revert: 撤销,版本回退8、perf: 性能优化9、test:测试10、improvement: 改进11、build: 打包12、ci: 持续集成13、update:更新
-
Composer registry manager基本使用汇总 https://github.com/slince/composer-registry-manager$ composer global require slince/composer-registry-manager ^2.0 $ composer repo:ls # 查看所有镜像 $ composer repo:use [imageName] # 使用某一个镜像,填写名称 $ composer install -vvv # 在项目下使用,安装项目所需要的依赖,-vvv显示详细信息 $ composer config -g repo.packagist composer [imageAddr] # 添加一个镜像服务1.镜像源修改后需要删除composer.lock文件,这里面锁定了原来是如何下载这些包的。
-