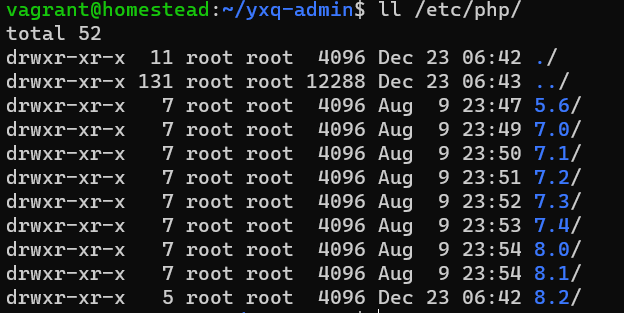
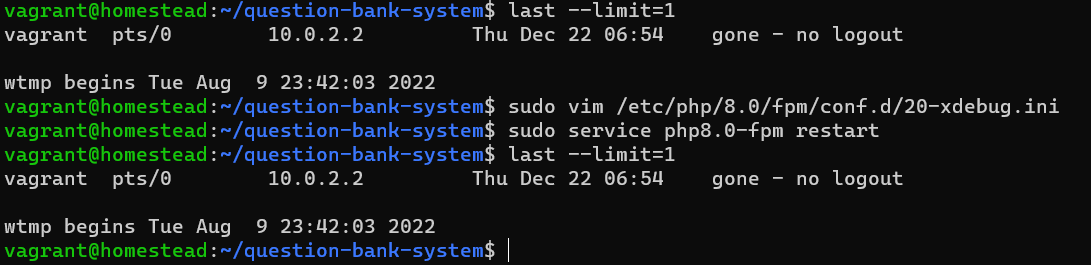
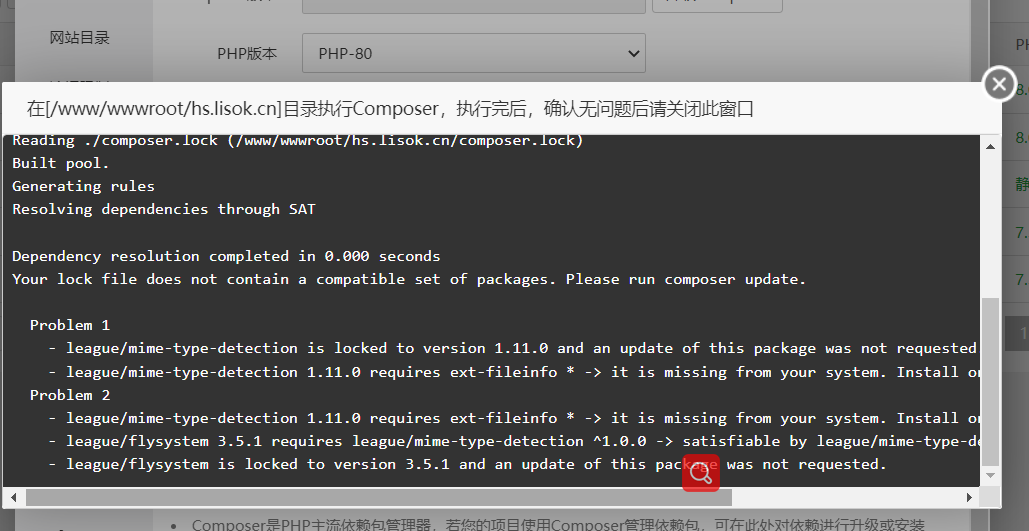
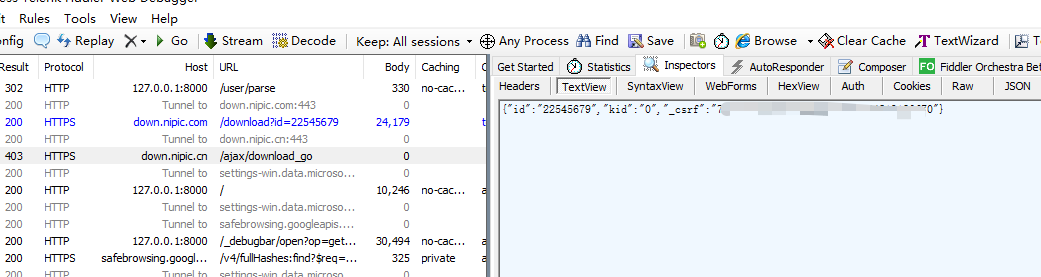
搜索到
18
篇与
的结果
-
 php-simple-html-dom-parser for PHP7.3 + If you use php 7.3 and higher, then use my edits. Otherwise, you will get errors due to migration to PCRE2 in new versions of PHP.For example: Warning: preg_match_all (): Compilation failed: invalid range in character class at offset 4fixapp\Utils\HtmlDomParser.php<?php namespace App\Utils; require 'simplehtmldom_1_5' . DIRECTORY_SEPARATOR . 'simple_html_dom.php'; class HtmlDomParser { static public function file_get_html($file) { return file_get_html($file); } static public function str_get_html($str) { return str_get_html($str); } }app\Utils\simplehtmldom_1_5\simple_html_dom.php<?php /** * Website: http://sourceforge.net/projects/simplehtmldom/ * Acknowledge: Jose Solorzano (https://sourceforge.net/projects/php-html/) * Contributions by: * Yousuke Kumakura (Attribute filters) * Vadim Voituk (Negative indexes supports of "find" method) * Antcs (Constructor with automatically load contents either text or file/url) * * all affected sections have comments starting with "PaperG" * * Paperg - Added case insensitive testing of the value of the selector. * Paperg - Added tag_start for the starting index of tags - NOTE: This works but not accurately. * This tag_start gets counted AFTER \r\n have been crushed out, and after the remove_noice calls so it will not reflect the REAL position of the tag in the source, * it will almost always be smaller by some amount. * We use this to determine how far into the file the tag in question is. This "percentage will never be accurate as the $dom->size is the "real" number of bytes the dom was created from. * but for most purposes, it's a really good estimation. * Paperg - Added the forceTagsClosed to the dom constructor. Forcing tags closed is great for malformed html, but it CAN lead to parsing errors. * Allow the user to tell us how much they trust the html. * Paperg add the text and plaintext to the selectors for the find syntax. plaintext implies text in the innertext of a node. text implies that the tag is a text node. * This allows for us to find tags based on the text they contain. * Create find_ancestor_tag to see if a tag is - at any level - inside of another specific tag. * Paperg: added parse_charset so that we know about the character set of the source document. * NOTE: If the user's system has a routine called get_last_retrieve_url_contents_content_type availalbe, we will assume it's returning the content-type header from the * last transfer or curl_exec, and we will parse that and use it in preference to any other method of charset detection. * * Licensed under The MIT License * Redistributions of files must retain the above copyright notice. * * @author S.C. Chen <[email protected]> * @author John Schlick * @author Rus Carroll * @version 1.11 ($Rev: 184 $) * @package PlaceLocalInclude * @subpackage simple_html_dom */ /** * All of the Defines for the classes below. * @author S.C. Chen <[email protected]> */ define('HDOM_TYPE_ELEMENT', 1); define('HDOM_TYPE_COMMENT', 2); define('HDOM_TYPE_TEXT', 3); define('HDOM_TYPE_ENDTAG', 4); define('HDOM_TYPE_ROOT', 5); define('HDOM_TYPE_UNKNOWN', 6); define('HDOM_QUOTE_DOUBLE', 0); define('HDOM_QUOTE_SINGLE', 1); define('HDOM_QUOTE_NO', 3); define('HDOM_INFO_BEGIN', 0); define('HDOM_INFO_END', 1); define('HDOM_INFO_QUOTE', 2); define('HDOM_INFO_SPACE', 3); define('HDOM_INFO_TEXT', 4); define('HDOM_INFO_INNER', 5); define('HDOM_INFO_OUTER', 6); define('HDOM_INFO_ENDSPACE', 7); define('DEFAULT_TARGET_CHARSET', 'UTF-8'); define('DEFAULT_BR_TEXT', "\r\n"); // helper functions // ----------------------------------------------------------------------------- // get html dom from file // $maxlen is defined in the code as PHP_STREAM_COPY_ALL which is defined as -1. function file_get_html($url, $use_include_path = false, $context = null, $offset = -1, $maxLen = -1, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { // We DO force the tags to be terminated. $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); // For sourceforge users: uncomment the next line and comment the retreive_url_contents line 2 lines down if it is not already done. $contents = file_get_contents($url, $use_include_path, $context, $offset); // Paperg - use our own mechanism for getting the contents as we want to control the timeout. // $contents = retrieve_url_contents($url); if (empty($contents)) { return false; } // The second parameter can force the selectors to all be lowercase. $dom->load($contents, $lowercase, $stripRN); return $dom; } // get html dom from string function str_get_html($str, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); if (empty($str)) { $dom->clear(); return false; } $dom->load($str, $lowercase, $stripRN); return $dom; } // dump html dom tree function dump_html_tree($node, $show_attr = true, $deep = 0) { $node->dump($node); } /** * simple html dom node * PaperG - added ability for "find" routine to lowercase the value of the selector. * PaperG - added $tag_start to track the start position of the tag in the total byte index * * @package PlaceLocalInclude */ class simple_html_dom_node { public $nodetype = HDOM_TYPE_TEXT; public $tag = 'text'; public $attr = array(); public $children = array(); public $nodes = array(); public $parent = null; public $_ = array(); public $tag_start = 0; private $dom = null; function __construct($dom) { $this->dom = $dom; $dom->nodes[] = $this; } function __destruct() { $this->clear(); } function __toString() { return $this->outertext(); } // clean up memory due to php5 circular references memory leak... function clear() { $this->dom = null; $this->nodes = null; $this->parent = null; $this->children = null; } // dump node's tree function dump($show_attr = true, $deep = 0) { $lead = str_repeat(' ', $deep); echo $lead . $this->tag; if ($show_attr && count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) echo "[$k]=>\"" . $this->$k . '", '; echo ')'; } echo "\n"; foreach ($this->nodes as $c) $c->dump($show_attr, $deep + 1); } // Debugging function to dump a single dom node with a bunch of information about it. function dump_node() { echo $this->tag; if (count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) { echo "[$k]=>\"" . $this->$k . '", '; } echo ')'; } if (count($this->attr) > 0) { echo ' $_ ('; foreach ($this->_ as $k => $v) { if (is_array($v)) { echo "[$k]=>("; foreach ($v as $k2 => $v2) { echo "[$k2]=>\"" . $v2 . '", '; } echo ")"; } else { echo "[$k]=>\"" . $v . '", '; } } echo ")"; } if (isset($this->text)) { echo " text: (" . $this->text . ")"; } echo " children: " . count($this->children); echo " nodes: " . count($this->nodes); echo " tag_start: " . $this->tag_start; echo "\n"; } // returns the parent of node function parent() { return $this->parent; } // returns children of node function children($idx = -1) { if ($idx === -1) return $this->children; if (isset($this->children[$idx])) return $this->children[$idx]; return null; } // returns the first child of node function first_child() { if (count($this->children) > 0) return $this->children[0]; return null; } // returns the last child of node function last_child() { if (($count = count($this->children)) > 0) return $this->children[$count - 1]; return null; } // returns the next sibling of node function next_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (++$idx >= $count) return null; return $this->parent->children[$idx]; } // returns the previous sibling of node function prev_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (--$idx < 0) return null; return $this->parent->children[$idx]; } // function to locate a specific ancestor tag in the path to the root. function find_ancestor_tag($tag) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // Start by including ourselves in the comparison. $returnDom = $this; while (!is_null($returnDom)) { if (is_object($debugObject)) { $debugObject->debugLog(2, "Current tag is: " . $returnDom->tag); } if ($returnDom->tag == $tag) { break; } $returnDom = $returnDom->parent; } return $returnDom; } // get dom node's inner html function innertext() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = ''; foreach ($this->nodes as $n) $ret .= $n->outertext(); return $ret; } // get dom node's outer text (with tag) function outertext() { global $debugObject; if (is_object($debugObject)) { $text = ''; if ($this->tag == 'text') { if (!empty($this->text)) { $text = " with text: " . $this->text; } } $debugObject->debugLog(1, 'Innertext of tag: ' . $this->tag . $text); } if ($this->tag === 'root') return $this->innertext(); // trigger callback if ($this->dom && $this->dom->callback !== null) { call_user_func_array($this->dom->callback, array($this)); } if (isset($this->_[HDOM_INFO_OUTER])) return $this->_[HDOM_INFO_OUTER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); // render begin tag if ($this->dom && $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]) { $ret = $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]->makeup(); } else { $ret = ""; } // render inner text if (isset($this->_[HDOM_INFO_INNER])) { // If it's a br tag... don't return the HDOM_INNER_INFO that we may or may not have added. if ($this->tag != "br") { $ret .= $this->_[HDOM_INFO_INNER]; } } else { if ($this->nodes) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->outertext()); } } } // render end tag if (isset($this->_[HDOM_INFO_END]) && $this->_[HDOM_INFO_END] != 0) $ret .= '</' . $this->tag . '>'; return $ret; } // get dom node's plain text function text() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; switch ($this->nodetype) { case HDOM_TYPE_TEXT: return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); case HDOM_TYPE_COMMENT: return ''; case HDOM_TYPE_UNKNOWN: return ''; } if (strcasecmp($this->tag, 'script') === 0) return ''; if (strcasecmp($this->tag, 'style') === 0) return ''; $ret = ''; // In rare cases, (always node type 1 or HDOM_TYPE_ELEMENT - observed for some span tags, and some p tags) $this->nodes is set to NULL. // NOTE: This indicates that there is a problem where it's set to NULL without a clear happening. // WHY is this happening? if (!is_null($this->nodes)) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->text()); } } return $ret; } function xmltext() { $ret = $this->innertext(); $ret = str_ireplace('<![CDATA[', '', $ret); $ret = str_replace(']]>', '', $ret); return $ret; } // build node's text with tag function makeup() { // text, comment, unknown if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = '<' . $this->tag; $i = -1; foreach ($this->attr as $key => $val) { ++$i; // skip removed attribute if ($val === null || $val === false) continue; $ret .= $this->_[HDOM_INFO_SPACE][$i][0]; //no value attr: nowrap, checked selected... if ($val === true) $ret .= $key; else { switch ($this->_[HDOM_INFO_QUOTE][$i]) { case HDOM_QUOTE_DOUBLE: $quote = '"'; break; case HDOM_QUOTE_SINGLE: $quote = '\''; break; default: $quote = ''; } $ret .= $key . $this->_[HDOM_INFO_SPACE][$i][1] . '=' . $this->_[HDOM_INFO_SPACE][$i][2] . $quote . $val . $quote; } } $ret = $this->dom->restore_noise($ret); return $ret . $this->_[HDOM_INFO_ENDSPACE] . '>'; } // find elements by css selector //PaperG - added ability for find to lowercase the value of the selector. function find($selector, $idx = null, $lowercase = false) { $selectors = $this->parse_selector($selector); if (($count = count($selectors)) === 0) return array(); $found_keys = array(); // find each selector for ($c = 0; $c < $count; ++$c) { // The change on the below line was documented on the sourceforge code tracker id 2788009 // used to be: if (($levle=count($selectors[0]))===0) return array(); if (($levle = count($selectors[$c])) === 0) return array(); if (!isset($this->_[HDOM_INFO_BEGIN])) return array(); $head = array($this->_[HDOM_INFO_BEGIN] => 1); // handle descendant selectors, no recursive! for ($l = 0; $l < $levle; ++$l) { $ret = array(); foreach ($head as $k => $v) { $n = ($k === -1) ? $this->dom->root : $this->dom->nodes[$k]; //PaperG - Pass this optional parameter on to the seek function. $n->seek($selectors[$c][$l], $ret, $lowercase); } $head = $ret; } foreach ($head as $k => $v) { if (!isset($found_keys[$k])) $found_keys[$k] = 1; } } // sort keys ksort($found_keys); $found = array(); foreach ($found_keys as $k => $v) $found[] = $this->dom->nodes[$k]; // return nth-element or array if (is_null($idx)) return $found; else if ($idx < 0) $idx = count($found) + $idx; return (isset($found[$idx])) ? $found[$idx] : null; } // seek for given conditions // PaperG - added parameter to allow for case insensitive testing of the value of a selector. protected function seek($selector, &$ret, $lowercase = false) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } list($tag, $key, $val, $exp, $no_key) = $selector; // xpath index if ($tag && $key && is_numeric($key)) { $count = 0; foreach ($this->children as $c) { if ($tag === '*' || $tag === $c->tag) { if (++$count == $key) { $ret[$c->_[HDOM_INFO_BEGIN]] = 1; return; } } } return; } $end = (!empty($this->_[HDOM_INFO_END])) ? $this->_[HDOM_INFO_END] : 0; if ($end == 0) { $parent = $this->parent; while (!isset($parent->_[HDOM_INFO_END]) && $parent !== null) { $end -= 1; $parent = $parent->parent; } $end += $parent->_[HDOM_INFO_END]; } for ($i = $this->_[HDOM_INFO_BEGIN] + 1; $i < $end; ++$i) { $node = $this->dom->nodes[$i]; $pass = true; if ($tag === '*' && !$key) { if (in_array($node, $this->children, true)) $ret[$i] = 1; continue; } // compare tag if ($tag && $tag != $node->tag && $tag !== '*') { $pass = false; } // compare key if ($pass && $key) { if ($no_key) { if (isset($node->attr[$key])) $pass = false; } else { if (($key != "plaintext") && !isset($node->attr[$key])) $pass = false; } } // compare value if ($pass && $key && $val && $val !== '*') { // If they have told us that this is a "plaintext" search then we want the plaintext of the node - right? if ($key == "plaintext") { // $node->plaintext actually returns $node->text(); $nodeKeyValue = $node->text(); } else { // this is a normal search, we want the value of that attribute of the tag. $nodeKeyValue = $node->attr[$key]; } if (is_object($debugObject)) { $debugObject->debugLog(2, "testing node: " . $node->tag . " for attribute: " . $key . $exp . $val . " where nodes value is: " . $nodeKeyValue); } //PaperG - If lowercase is set, do a case insensitive test of the value of the selector. if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($nodeKeyValue)); } else { $check = $this->match($exp, $val, $nodeKeyValue); } if (is_object($debugObject)) { $debugObject->debugLog(2, "after match: " . ($check ? "true" : "false")); } // handle multiple class if (!$check && strcasecmp($key, 'class') === 0) { foreach (explode(' ', $node->attr[$key]) as $k) { // Without this, there were cases where leading, trailing, or double spaces lead to our comparing blanks - bad form. if (!empty($k)) { if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($k)); } else { $check = $this->match($exp, $val, $k); } if ($check) break; } } } if (!$check) $pass = false; } if ($pass) $ret[$i] = 1; unset($node); } // It's passed by reference so this is actually what this function returns. if (is_object($debugObject)) { $debugObject->debugLog(1, "EXIT - ret: ", $ret); } } protected function match($exp, $pattern, $value) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } switch ($exp) { case '=': return ($value === $pattern); case '!=': return ($value !== $pattern); case '^=': return preg_match("/^" . preg_quote($pattern, '/') . "/", $value); case '$=': return preg_match("/" . preg_quote($pattern, '/') . "$/", $value); case '*=': if ($pattern[0] == '/') { return preg_match($pattern, $value); } return preg_match("/" . $pattern . "/i", $value); } return false; } protected function parse_selector($selector_string) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // pattern of CSS selectors, modified from mootools // Paperg: Add the colon to the attrbute, so that it properly finds <tag attr:ibute="something" > like google does. // Note: if you try to look at this attribute, yo MUST use getAttribute since $dom->x:y will fail the php syntax check. // Notice the \[ starting the attbute? and the @? following? This implies that an attribute can begin with an @ sign that is not captured. // This implies that an html attribute specifier may start with an @ sign that is NOT captured by the expression. // farther study is required to determine of this should be documented or removed. // $pattern = "/([\w-:\*]*)(?:\#([\w-]+)|\.([\w-]+))?(?:\[@?(!?[\w-]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; $pattern = "/([\w\-:\*]*)(?:\#([\w\-]+)|\.([\w\-]+))?(?:\[@?(!?[\w\-:]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; preg_match_all($pattern, trim($selector_string) . ' simple_html_dom.php', $matches, PREG_SET_ORDER); if (is_object($debugObject)) { $debugObject->debugLog(2, "Matches Array: ", $matches); } $selectors = array(); $result = array(); //print_r($matches); foreach ($matches as $m) { $m[0] = trim($m[0]); if ($m[0] === '' || $m[0] === '/' || $m[0] === '//') continue; // for browser generated xpath if ($m[1] === 'tbody') continue; list($tag, $key, $val, $exp, $no_key) = array($m[1], null, null, '=', false); if (!empty($m[2])) { $key = 'id'; $val = $m[2]; } if (!empty($m[3])) { $key = 'class'; $val = $m[3]; } if (!empty($m[4])) { $key = $m[4]; } if (!empty($m[5])) { $exp = $m[5]; } if (!empty($m[6])) { $val = $m[6]; } // convert to lowercase if ($this->dom->lowercase) { $tag = strtolower($tag); $key = strtolower($key); } //elements that do NOT have the specified attribute if (isset($key[0]) && $key[0] === '!') { $key = substr($key, 1); $no_key = true; } $result[] = array($tag, $key, $val, $exp, $no_key); if (trim($m[7]) === ',') { $selectors[] = $result; $result = array(); } } if (count($result) > 0) $selectors[] = $result; return $selectors; } function __get($name) { if (isset($this->attr[$name])) { return $this->convert_text($this->attr[$name]); } switch ($name) { case 'outertext': return $this->outertext(); case 'innertext': return $this->innertext(); case 'plaintext': return $this->text(); case 'xmltext': return $this->xmltext(); default: return array_key_exists($name, $this->attr); } } function __set($name, $value) { switch ($name) { case 'outertext': return $this->_[HDOM_INFO_OUTER] = $value; case 'innertext': if (isset($this->_[HDOM_INFO_TEXT])) return $this->_[HDOM_INFO_TEXT] = $value; return $this->_[HDOM_INFO_INNER] = $value; } if (!isset($this->attr[$name])) { $this->_[HDOM_INFO_SPACE][] = array(' ', '', ''); $this->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; } $this->attr[$name] = $value; } function __isset($name) { switch ($name) { case 'outertext': return true; case 'innertext': return true; case 'plaintext': return true; } //no value attr: nowrap, checked selected... return (array_key_exists($name, $this->attr)) ? true : isset($this->attr[$name]); } function __unset($name) { if (isset($this->attr[$name])) unset($this->attr[$name]); } // PaperG - Function to convert the text from one character set to another if the two sets are not the same. function convert_text($text) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } $converted_text = $text; $sourceCharset = ""; $targetCharset = ""; if ($this->dom) { $sourceCharset = strtoupper($this->dom->_charset); $targetCharset = strtoupper($this->dom->_target_charset); } if (is_object($debugObject)) { $debugObject->debugLog(3, "source charset: " . $sourceCharset . " target charaset: " . $targetCharset); } if (!empty($sourceCharset) && !empty($targetCharset) && (strcasecmp($sourceCharset, $targetCharset) != 0)) { // Check if the reported encoding could have been incorrect and the text is actually already UTF-8 if ((strcasecmp($targetCharset, 'UTF-8') == 0) && ($this->is_utf8($text))) { $converted_text = $text; } else { $converted_text = iconv($sourceCharset, $targetCharset, $text); } } return $converted_text; } function is_utf8($string) { return (utf8_encode(utf8_decode($string)) == $string); } // camel naming conventions function getAllAttributes() { return $this->attr; } function getAttribute($name) { return $this->__get($name); } function setAttribute($name, $value) { $this->__set($name, $value); } function hasAttribute($name) { return $this->__isset($name); } function removeAttribute($name) { $this->__set($name, null); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = null) { return $this->find($name, $idx); } function parentNode() { return $this->parent(); } function childNodes($idx = -1) { return $this->children($idx); } function firstChild() { return $this->first_child(); } function lastChild() { return $this->last_child(); } function nextSibling() { return $this->next_sibling(); } function previousSibling() { return $this->prev_sibling(); } } /** * simple html dom parser * Paperg - in the find routine: allow us to specify that we want case insensitive testing of the value of the selector. * Paperg - change $size from protected to public so we can easily access it * Paperg - added ForceTagsClosed in the constructor which tells us whether we trust the html or not. Default is to NOT trust it. * * @package PlaceLocalInclude */ class simple_html_dom { public $root = null; public $nodes = array(); public $callback = null; public $lowercase = false; public $size; protected $pos; protected $doc; protected $char; protected $cursor; protected $parent; protected $noise = array(); protected $token_blank = " \t\r\n"; protected $token_equal = ' =/>'; protected $token_slash = " />\r\n\t"; protected $token_attr = ' >'; protected $_charset = ''; protected $_target_charset = ''; protected $default_br_text = ""; // use isset instead of in_array, performance boost about 30%... protected $self_closing_tags = array('img' => 1, 'br' => 1, 'input' => 1, 'meta' => 1, 'link' => 1, 'hr' => 1, 'base' => 1, 'embed' => 1, 'spacer' => 1); protected $block_tags = array('root' => 1, 'body' => 1, 'form' => 1, 'div' => 1, 'span' => 1, 'table' => 1); // Known sourceforge issue #2977341 // B tags that are not closed cause us to return everything to the end of the document. protected $optional_closing_tags = array( 'tr' => array('tr' => 1, 'td' => 1, 'th' => 1), 'th' => array('th' => 1), 'td' => array('td' => 1), 'li' => array('li' => 1), 'dt' => array('dt' => 1, 'dd' => 1), 'dd' => array('dd' => 1, 'dt' => 1), 'dl' => array('dd' => 1, 'dt' => 1), 'p' => array('p' => 1), 'nobr' => array('nobr' => 1), 'b' => array('b' => 1), ); function __construct($str = null, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { if ($str) { if (preg_match("/^http:\/\//i", $str) || is_file($str)) $this->load_file($str); else $this->load($str, $lowercase, $stripRN, $defaultBRText); } // Forcing tags to be closed implies that we don't trust the html, but it can lead to parsing errors if we SHOULD trust the html. if (!$forceTagsClosed) { $this->optional_closing_array = array(); } $this->_target_charset = $target_charset; } function __destruct() { $this->clear(); } // load html from string function load($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { global $debugObject; // prepare $this->prepare($str, $lowercase, $stripRN, $defaultBRText); // strip out comments $this->remove_noise("'<!--(.*?)-->'is"); // strip out cdata $this->remove_noise("'<!\[CDATA\[(.*?)\]\]>'is", true); // Per sourceforge http://sourceforge.net/tracker/?func=detail&aid=2949097&group_id=218559&atid=1044037 // Script tags removal now preceeds style tag removal. // strip out <script> tags $this->remove_noise("'<\s*script[^>]*[^/]>(.*?)<\s*/\s*script\s*>'is"); $this->remove_noise("'<\s*script\s*>(.*?)<\s*/\s*script\s*>'is"); // strip out <style> tags $this->remove_noise("'<\s*style[^>]*[^/]>(.*?)<\s*/\s*style\s*>'is"); $this->remove_noise("'<\s*style\s*>(.*?)<\s*/\s*style\s*>'is"); // strip out preformatted tags $this->remove_noise("'<\s*(?:code)[^>]*>(.*?)<\s*/\s*(?:code)\s*>'is"); // strip out server side scripts $this->remove_noise("'(<\?)(.*?)(\?>)'s", true); // strip smarty scripts $this->remove_noise("'(\{\w)(.*?)(\})'s", true); // parsing while ($this->parse()) ; // end $this->root->_[HDOM_INFO_END] = $this->cursor; $this->parse_charset(); } // load html from file function load_file() { $args = func_get_args(); $this->load(call_user_func_array('file_get_contents', $args), true); // Per the simple_html_dom repositiry this is a planned upgrade to the codebase. // Throw an error if we can't properly load the dom. if (($error = error_get_last()) !== null) { $this->clear(); return false; } } // set callback function function set_callback($function_name) { $this->callback = $function_name; } // remove callback function function remove_callback() { $this->callback = null; } // save dom as string function save($filepath = '') { $ret = $this->root->innertext(); if ($filepath !== '') file_put_contents($filepath, $ret, LOCK_EX); return $ret; } // find dom node by css selector // Paperg - allow us to specify that we want case insensitive testing of the value of the selector. function find($selector, $idx = null, $lowercase = false) { return $this->root->find($selector, $idx, $lowercase); } // clean up memory due to php5 circular references memory leak... function clear() { foreach ($this->nodes as $n) { $n->clear(); $n = null; } // This add next line is documented in the sourceforge repository. 2977248 as a fix for ongoing memory leaks that occur even with the use of clear. if (isset($this->children)) foreach ($this->children as $n) { $n->clear(); $n = null; } if (isset($this->parent)) { $this->parent->clear(); unset($this->parent); } if (isset($this->root)) { $this->root->clear(); unset($this->root); } unset($this->doc); unset($this->noise); } function dump($show_attr = true) { $this->root->dump($show_attr); } // prepare HTML data and init everything protected function prepare($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $this->clear(); // set the length of content before we do anything to it. $this->size = strlen($str); //before we save the string as the doc... strip out the \r \n's if we are told to. if ($stripRN) { $str = str_replace("\r", " ", $str); $str = str_replace("\n", " ", $str); } $this->doc = $str; $this->pos = 0; $this->cursor = 1; $this->noise = array(); $this->nodes = array(); $this->lowercase = $lowercase; $this->default_br_text = $defaultBRText; $this->root = new simple_html_dom_node($this); $this->root->tag = 'root'; $this->root->_[HDOM_INFO_BEGIN] = -1; $this->root->nodetype = HDOM_TYPE_ROOT; $this->parent = $this->root; if ($this->size > 0) $this->char = $this->doc[0]; } // parse html content protected function parse() { if (($s = $this->copy_until_char('<')) === '') return $this->read_tag(); // text $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = $s; $this->link_nodes($node, false); return true; } // PAPERG - dkchou - added this to try to identify the character set of the page we have just parsed so we know better how to spit it out later. // NOTE: IF you provide a routine called get_last_retrieve_url_contents_content_type which returns the CURLINFO_CONTENT_TYPE fromt he last curl_exec // (or the content_type header fromt eh last transfer), we will parse THAT, and if a charset is specified, we will use it over any other mechanism. protected function parse_charset() { global $debugObject; $charset = null; if (function_exists('get_last_retrieve_url_contents_content_type')) { $contentTypeHeader = get_last_retrieve_url_contents_content_type(); $success = preg_match('/charset=(.+)/', $contentTypeHeader, $matches); if ($success) { $charset = $matches[1]; if (is_object($debugObject)) { $debugObject->debugLog(2, 'header content-type found charset of: ' . $charset); } } } if (empty($charset)) { $el = $this->root->find('meta[http-equiv=Content-Type]', 0); if (!empty($el)) { $fullvalue = $el->content; if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag found' . $fullValue); } if (!empty($fullvalue)) { $success = preg_match('/charset=(.+)/', $fullvalue, $matches); if ($success) { $charset = $matches[1]; } else { // If there is a meta tag, and they don't specify the character set, research says that it's typically ISO-8859-1 if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag couldn\'t be parsed. using iso-8859 default.'); } $charset = 'ISO-8859-1'; } } } } // If we couldn't find a charset above, then lets try to detect one based on the text we got... if (empty($charset)) { // Have php try to detect the encoding from the text given to us. $charset = mb_detect_encoding($this->root->plaintext . "ascii", $encoding_list = array("UTF-8", "CP1252")); if (is_object($debugObject)) { $debugObject->debugLog(2, 'mb_detect found: ' . $charset); } // and if this doesn't work... then we need to just wrongheadedly assume it's UTF-8 so that we can move on - cause this will usually give us most of what we need... if ($charset === false) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'since mb_detect failed - using default of utf-8'); } $charset = 'UTF-8'; } } // Since CP1252 is a superset, if we get one of it's subsets, we want it instead. if ((strtolower($charset) == strtolower('ISO-8859-1')) || (strtolower($charset) == strtolower('Latin1')) || (strtolower($charset) == strtolower('Latin-1'))) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'replacing ' . $charset . ' with CP1252 as its a superset'); } $charset = 'CP1252'; } if (is_object($debugObject)) { $debugObject->debugLog(1, 'EXIT - ' . $charset); } return $this->_charset = $charset; } // read tag info protected function read_tag() { if ($this->char !== '<') { $this->root->_[HDOM_INFO_END] = $this->cursor; return false; } $begin_tag_pos = $this->pos; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // end tag if ($this->char === '/') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // This represetns the change in the simple_html_dom trunk from revision 180 to 181. // $this->skip($this->token_blank_t); $this->skip($this->token_blank); $tag = $this->copy_until_char('>'); // skip attributes in end tag if (($pos = strpos($tag, ' ')) !== false) $tag = substr($tag, 0, $pos); $parent_lower = strtolower($this->parent->tag); $tag_lower = strtolower($tag); if ($parent_lower !== $tag_lower) { if (isset($this->optional_closing_tags[$parent_lower]) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent if ($this->parent->parent) $this->parent = $this->parent->parent; $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && strtolower($this->parent->parent->tag) === $tag_lower) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } else return $this->as_text_node($tag); } $this->parent->_[HDOM_INFO_END] = $this->cursor; if ($this->parent->parent) $this->parent = $this->parent->parent; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } $node = new simple_html_dom_node($this); $node->_[HDOM_INFO_BEGIN] = $this->cursor; ++$this->cursor; $tag = $this->copy_until($this->token_slash); $node->tag_start = $begin_tag_pos; // doctype, cdata & comments... if (isset($tag[0]) && $tag[0] === '!') { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until_char('>'); if (isset($tag[2]) && $tag[1] === '-' && $tag[2] === '-') { $node->nodetype = HDOM_TYPE_COMMENT; $node->tag = 'comment'; } else { $node->nodetype = HDOM_TYPE_UNKNOWN; $node->tag = 'unknown'; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, true); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // text if ($pos = strpos($tag, '<') !== false) { $tag = '<' . substr($tag, 0, -1); $node->_[HDOM_INFO_TEXT] = $tag; $this->link_nodes($node, false); $this->char = $this->doc[--$this->pos]; // prev return true; } if (!preg_match("/^[\w\-:]+$/", $tag)) { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until('<>'); if ($this->char === '<') { $this->link_nodes($node, false); return true; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // begin tag $node->nodetype = HDOM_TYPE_ELEMENT; $tag_lower = strtolower($tag); $node->tag = ($this->lowercase) ? $tag_lower : $tag; // handle optional closing tags if (isset($this->optional_closing_tags[$tag_lower])) { while (isset($this->optional_closing_tags[$tag_lower][strtolower($this->parent->tag)])) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } $node->parent = $this->parent; } $guard = 0; // prevent infinity loop $space = array($this->copy_skip($this->token_blank), '', ''); // attributes do { if ($this->char !== null && $space[0] === '') break; $name = $this->copy_until($this->token_equal); if ($guard === $this->pos) { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next continue; } $guard = $this->pos; // handle endless '<' if ($this->pos >= $this->size - 1 && $this->char !== '>') { $node->nodetype = HDOM_TYPE_TEXT; $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = '<' . $tag . $space[0] . $name; $node->tag = 'text'; $this->link_nodes($node, false); return true; } // handle mismatch '<' if ($this->doc[$this->pos - 1] == '<') { $node->nodetype = HDOM_TYPE_TEXT; $node->tag = 'text'; $node->attr = array(); $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = substr($this->doc, $begin_tag_pos, $this->pos - $begin_tag_pos - 1); $this->pos -= 2; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->link_nodes($node, false); return true; } if ($name !== '/' && $name !== '') { $space[1] = $this->copy_skip($this->token_blank); $name = $this->restore_noise($name); if ($this->lowercase) $name = strtolower($name); if ($this->char === '=') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->parse_attr($node, $name, $space); } else { //no value attr: nowrap, checked selected... $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = true; if ($this->char != '>') $this->char = $this->doc[--$this->pos]; // prev } $node->_[HDOM_INFO_SPACE][] = $space; $space = array($this->copy_skip($this->token_blank), '', ''); } else break; } while ($this->char !== '>' && $this->char !== '/'); $this->link_nodes($node, true); $node->_[HDOM_INFO_ENDSPACE] = $space[0]; // check self closing if ($this->copy_until_char_escape('>') === '/') { $node->_[HDOM_INFO_ENDSPACE] .= '/'; $node->_[HDOM_INFO_END] = 0; } else { // reset parent if (!isset($this->self_closing_tags[strtolower($node->tag)])) $this->parent = $node; } $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // If it's a BR tag, we need to set it's text to the default text. // This way when we see it in plaintext, we can generate formatting that the user wants. if ($node->tag == "br") { $node->_[HDOM_INFO_INNER] = $this->default_br_text; } return true; } // parse attributes protected function parse_attr($node, $name, &$space) { // Per sourceforge: http://sourceforge.net/tracker/?func=detail&aid=3061408&group_id=218559&atid=1044037 // If the attribute is already defined inside a tag, only pay atetntion to the first one as opposed to the last one. if (isset($node->attr[$name])) { return; } $space[2] = $this->copy_skip($this->token_blank); switch ($this->char) { case '"': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('"')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; case '\'': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_SINGLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('\'')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; default: $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = $this->restore_noise($this->copy_until($this->token_attr)); } // PaperG: Attributes should not have \r or \n in them, that counts as html whitespace. $node->attr[$name] = str_replace("\r", "", $node->attr[$name]); $node->attr[$name] = str_replace("\n", "", $node->attr[$name]); // PaperG: If this is a "class" selector, lets get rid of the preceeding and trailing space since some people leave it in the multi class case. if ($name == "class") { $node->attr[$name] = trim($node->attr[$name]); } } // link node's parent protected function link_nodes(&$node, $is_child) { $node->parent = $this->parent; $this->parent->nodes[] = $node; if ($is_child) $this->parent->children[] = $node; } // as a text node protected function as_text_node($tag) { $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = '</' . $tag . '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } protected function skip($chars) { $this->pos += strspn($this->doc, $chars, $this->pos); $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next } protected function copy_skip($chars) { $pos = $this->pos; $len = strspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next if ($len === 0) return ''; return substr($this->doc, $pos, $len); } protected function copy_until($chars) { $pos = $this->pos; $len = strcspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return substr($this->doc, $pos, $len); } protected function copy_until_char($char) { if ($this->char === null) return ''; if (($pos = strpos($this->doc, $char, $this->pos)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } protected function copy_until_char_escape($char) { if ($this->char === null) return ''; $start = $this->pos; while (1) { if (($pos = strpos($this->doc, $char, $start)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; if ($this->doc[$pos - 1] === '\\') { $start = $pos + 1; continue; } $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } } // remove noise from html content protected function remove_noise($pattern, $remove_tag = false) { $count = preg_match_all($pattern, $this->doc, $matches, PREG_SET_ORDER | PREG_OFFSET_CAPTURE); for ($i = $count - 1; $i > -1; --$i) { $key = '___noise___' . sprintf('% 3d', count($this->noise) + 100); $idx = ($remove_tag) ? 0 : 1; $this->noise[$key] = $matches[$i][$idx][0]; $this->doc = substr_replace($this->doc, $key, $matches[$i][$idx][1], strlen($matches[$i][$idx][0])); } // reset the length of content $this->size = strlen($this->doc); if ($this->size > 0) $this->char = $this->doc[0]; } // restore noise to html content function restore_noise($text) { while (($pos = strpos($text, '___noise___')) !== false) { $key = '___noise___' . $text[$pos + 11] . $text[$pos + 12] . $text[$pos + 13]; if (isset($this->noise[$key])) // $text = simple_html_dom . phpsubstr($text, 0, $pos) . $this->noise[$key] . substr($text, $pos + 14); $text = substr($text, 0, $pos).$this->noise[$key].substr($text, $pos+14); } return $text; } function __toString() { return $this->root->innertext(); } function __get($name) { switch ($name) { case 'outertext': return $this->root->innertext(); case 'innertext': return $this->root->innertext(); case 'plaintext': return $this->root->text(); case 'charset': return $this->_charset; case 'target_charset': return $this->_target_charset; } } // camel naming conventions function childNodes($idx = -1) { return $this->root->childNodes($idx); } function firstChild() { return $this->root->first_child(); } function lastChild() { return $this->root->last_child(); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = -1) { return $this->find($name, $idx); } function loadFile() { $args = func_get_args(); $this->load_file($args); } } ?> 引用1.php-simple-html-dom-parser for PHP7.3 +:https://github.com/sunra/php-simple-html-dom-parser/issues/75
php-simple-html-dom-parser for PHP7.3 + If you use php 7.3 and higher, then use my edits. Otherwise, you will get errors due to migration to PCRE2 in new versions of PHP.For example: Warning: preg_match_all (): Compilation failed: invalid range in character class at offset 4fixapp\Utils\HtmlDomParser.php<?php namespace App\Utils; require 'simplehtmldom_1_5' . DIRECTORY_SEPARATOR . 'simple_html_dom.php'; class HtmlDomParser { static public function file_get_html($file) { return file_get_html($file); } static public function str_get_html($str) { return str_get_html($str); } }app\Utils\simplehtmldom_1_5\simple_html_dom.php<?php /** * Website: http://sourceforge.net/projects/simplehtmldom/ * Acknowledge: Jose Solorzano (https://sourceforge.net/projects/php-html/) * Contributions by: * Yousuke Kumakura (Attribute filters) * Vadim Voituk (Negative indexes supports of "find" method) * Antcs (Constructor with automatically load contents either text or file/url) * * all affected sections have comments starting with "PaperG" * * Paperg - Added case insensitive testing of the value of the selector. * Paperg - Added tag_start for the starting index of tags - NOTE: This works but not accurately. * This tag_start gets counted AFTER \r\n have been crushed out, and after the remove_noice calls so it will not reflect the REAL position of the tag in the source, * it will almost always be smaller by some amount. * We use this to determine how far into the file the tag in question is. This "percentage will never be accurate as the $dom->size is the "real" number of bytes the dom was created from. * but for most purposes, it's a really good estimation. * Paperg - Added the forceTagsClosed to the dom constructor. Forcing tags closed is great for malformed html, but it CAN lead to parsing errors. * Allow the user to tell us how much they trust the html. * Paperg add the text and plaintext to the selectors for the find syntax. plaintext implies text in the innertext of a node. text implies that the tag is a text node. * This allows for us to find tags based on the text they contain. * Create find_ancestor_tag to see if a tag is - at any level - inside of another specific tag. * Paperg: added parse_charset so that we know about the character set of the source document. * NOTE: If the user's system has a routine called get_last_retrieve_url_contents_content_type availalbe, we will assume it's returning the content-type header from the * last transfer or curl_exec, and we will parse that and use it in preference to any other method of charset detection. * * Licensed under The MIT License * Redistributions of files must retain the above copyright notice. * * @author S.C. Chen <[email protected]> * @author John Schlick * @author Rus Carroll * @version 1.11 ($Rev: 184 $) * @package PlaceLocalInclude * @subpackage simple_html_dom */ /** * All of the Defines for the classes below. * @author S.C. Chen <[email protected]> */ define('HDOM_TYPE_ELEMENT', 1); define('HDOM_TYPE_COMMENT', 2); define('HDOM_TYPE_TEXT', 3); define('HDOM_TYPE_ENDTAG', 4); define('HDOM_TYPE_ROOT', 5); define('HDOM_TYPE_UNKNOWN', 6); define('HDOM_QUOTE_DOUBLE', 0); define('HDOM_QUOTE_SINGLE', 1); define('HDOM_QUOTE_NO', 3); define('HDOM_INFO_BEGIN', 0); define('HDOM_INFO_END', 1); define('HDOM_INFO_QUOTE', 2); define('HDOM_INFO_SPACE', 3); define('HDOM_INFO_TEXT', 4); define('HDOM_INFO_INNER', 5); define('HDOM_INFO_OUTER', 6); define('HDOM_INFO_ENDSPACE', 7); define('DEFAULT_TARGET_CHARSET', 'UTF-8'); define('DEFAULT_BR_TEXT', "\r\n"); // helper functions // ----------------------------------------------------------------------------- // get html dom from file // $maxlen is defined in the code as PHP_STREAM_COPY_ALL which is defined as -1. function file_get_html($url, $use_include_path = false, $context = null, $offset = -1, $maxLen = -1, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { // We DO force the tags to be terminated. $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); // For sourceforge users: uncomment the next line and comment the retreive_url_contents line 2 lines down if it is not already done. $contents = file_get_contents($url, $use_include_path, $context, $offset); // Paperg - use our own mechanism for getting the contents as we want to control the timeout. // $contents = retrieve_url_contents($url); if (empty($contents)) { return false; } // The second parameter can force the selectors to all be lowercase. $dom->load($contents, $lowercase, $stripRN); return $dom; } // get html dom from string function str_get_html($str, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); if (empty($str)) { $dom->clear(); return false; } $dom->load($str, $lowercase, $stripRN); return $dom; } // dump html dom tree function dump_html_tree($node, $show_attr = true, $deep = 0) { $node->dump($node); } /** * simple html dom node * PaperG - added ability for "find" routine to lowercase the value of the selector. * PaperG - added $tag_start to track the start position of the tag in the total byte index * * @package PlaceLocalInclude */ class simple_html_dom_node { public $nodetype = HDOM_TYPE_TEXT; public $tag = 'text'; public $attr = array(); public $children = array(); public $nodes = array(); public $parent = null; public $_ = array(); public $tag_start = 0; private $dom = null; function __construct($dom) { $this->dom = $dom; $dom->nodes[] = $this; } function __destruct() { $this->clear(); } function __toString() { return $this->outertext(); } // clean up memory due to php5 circular references memory leak... function clear() { $this->dom = null; $this->nodes = null; $this->parent = null; $this->children = null; } // dump node's tree function dump($show_attr = true, $deep = 0) { $lead = str_repeat(' ', $deep); echo $lead . $this->tag; if ($show_attr && count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) echo "[$k]=>\"" . $this->$k . '", '; echo ')'; } echo "\n"; foreach ($this->nodes as $c) $c->dump($show_attr, $deep + 1); } // Debugging function to dump a single dom node with a bunch of information about it. function dump_node() { echo $this->tag; if (count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) { echo "[$k]=>\"" . $this->$k . '", '; } echo ')'; } if (count($this->attr) > 0) { echo ' $_ ('; foreach ($this->_ as $k => $v) { if (is_array($v)) { echo "[$k]=>("; foreach ($v as $k2 => $v2) { echo "[$k2]=>\"" . $v2 . '", '; } echo ")"; } else { echo "[$k]=>\"" . $v . '", '; } } echo ")"; } if (isset($this->text)) { echo " text: (" . $this->text . ")"; } echo " children: " . count($this->children); echo " nodes: " . count($this->nodes); echo " tag_start: " . $this->tag_start; echo "\n"; } // returns the parent of node function parent() { return $this->parent; } // returns children of node function children($idx = -1) { if ($idx === -1) return $this->children; if (isset($this->children[$idx])) return $this->children[$idx]; return null; } // returns the first child of node function first_child() { if (count($this->children) > 0) return $this->children[0]; return null; } // returns the last child of node function last_child() { if (($count = count($this->children)) > 0) return $this->children[$count - 1]; return null; } // returns the next sibling of node function next_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (++$idx >= $count) return null; return $this->parent->children[$idx]; } // returns the previous sibling of node function prev_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (--$idx < 0) return null; return $this->parent->children[$idx]; } // function to locate a specific ancestor tag in the path to the root. function find_ancestor_tag($tag) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // Start by including ourselves in the comparison. $returnDom = $this; while (!is_null($returnDom)) { if (is_object($debugObject)) { $debugObject->debugLog(2, "Current tag is: " . $returnDom->tag); } if ($returnDom->tag == $tag) { break; } $returnDom = $returnDom->parent; } return $returnDom; } // get dom node's inner html function innertext() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = ''; foreach ($this->nodes as $n) $ret .= $n->outertext(); return $ret; } // get dom node's outer text (with tag) function outertext() { global $debugObject; if (is_object($debugObject)) { $text = ''; if ($this->tag == 'text') { if (!empty($this->text)) { $text = " with text: " . $this->text; } } $debugObject->debugLog(1, 'Innertext of tag: ' . $this->tag . $text); } if ($this->tag === 'root') return $this->innertext(); // trigger callback if ($this->dom && $this->dom->callback !== null) { call_user_func_array($this->dom->callback, array($this)); } if (isset($this->_[HDOM_INFO_OUTER])) return $this->_[HDOM_INFO_OUTER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); // render begin tag if ($this->dom && $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]) { $ret = $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]->makeup(); } else { $ret = ""; } // render inner text if (isset($this->_[HDOM_INFO_INNER])) { // If it's a br tag... don't return the HDOM_INNER_INFO that we may or may not have added. if ($this->tag != "br") { $ret .= $this->_[HDOM_INFO_INNER]; } } else { if ($this->nodes) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->outertext()); } } } // render end tag if (isset($this->_[HDOM_INFO_END]) && $this->_[HDOM_INFO_END] != 0) $ret .= '</' . $this->tag . '>'; return $ret; } // get dom node's plain text function text() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; switch ($this->nodetype) { case HDOM_TYPE_TEXT: return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); case HDOM_TYPE_COMMENT: return ''; case HDOM_TYPE_UNKNOWN: return ''; } if (strcasecmp($this->tag, 'script') === 0) return ''; if (strcasecmp($this->tag, 'style') === 0) return ''; $ret = ''; // In rare cases, (always node type 1 or HDOM_TYPE_ELEMENT - observed for some span tags, and some p tags) $this->nodes is set to NULL. // NOTE: This indicates that there is a problem where it's set to NULL without a clear happening. // WHY is this happening? if (!is_null($this->nodes)) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->text()); } } return $ret; } function xmltext() { $ret = $this->innertext(); $ret = str_ireplace('<![CDATA[', '', $ret); $ret = str_replace(']]>', '', $ret); return $ret; } // build node's text with tag function makeup() { // text, comment, unknown if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = '<' . $this->tag; $i = -1; foreach ($this->attr as $key => $val) { ++$i; // skip removed attribute if ($val === null || $val === false) continue; $ret .= $this->_[HDOM_INFO_SPACE][$i][0]; //no value attr: nowrap, checked selected... if ($val === true) $ret .= $key; else { switch ($this->_[HDOM_INFO_QUOTE][$i]) { case HDOM_QUOTE_DOUBLE: $quote = '"'; break; case HDOM_QUOTE_SINGLE: $quote = '\''; break; default: $quote = ''; } $ret .= $key . $this->_[HDOM_INFO_SPACE][$i][1] . '=' . $this->_[HDOM_INFO_SPACE][$i][2] . $quote . $val . $quote; } } $ret = $this->dom->restore_noise($ret); return $ret . $this->_[HDOM_INFO_ENDSPACE] . '>'; } // find elements by css selector //PaperG - added ability for find to lowercase the value of the selector. function find($selector, $idx = null, $lowercase = false) { $selectors = $this->parse_selector($selector); if (($count = count($selectors)) === 0) return array(); $found_keys = array(); // find each selector for ($c = 0; $c < $count; ++$c) { // The change on the below line was documented on the sourceforge code tracker id 2788009 // used to be: if (($levle=count($selectors[0]))===0) return array(); if (($levle = count($selectors[$c])) === 0) return array(); if (!isset($this->_[HDOM_INFO_BEGIN])) return array(); $head = array($this->_[HDOM_INFO_BEGIN] => 1); // handle descendant selectors, no recursive! for ($l = 0; $l < $levle; ++$l) { $ret = array(); foreach ($head as $k => $v) { $n = ($k === -1) ? $this->dom->root : $this->dom->nodes[$k]; //PaperG - Pass this optional parameter on to the seek function. $n->seek($selectors[$c][$l], $ret, $lowercase); } $head = $ret; } foreach ($head as $k => $v) { if (!isset($found_keys[$k])) $found_keys[$k] = 1; } } // sort keys ksort($found_keys); $found = array(); foreach ($found_keys as $k => $v) $found[] = $this->dom->nodes[$k]; // return nth-element or array if (is_null($idx)) return $found; else if ($idx < 0) $idx = count($found) + $idx; return (isset($found[$idx])) ? $found[$idx] : null; } // seek for given conditions // PaperG - added parameter to allow for case insensitive testing of the value of a selector. protected function seek($selector, &$ret, $lowercase = false) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } list($tag, $key, $val, $exp, $no_key) = $selector; // xpath index if ($tag && $key && is_numeric($key)) { $count = 0; foreach ($this->children as $c) { if ($tag === '*' || $tag === $c->tag) { if (++$count == $key) { $ret[$c->_[HDOM_INFO_BEGIN]] = 1; return; } } } return; } $end = (!empty($this->_[HDOM_INFO_END])) ? $this->_[HDOM_INFO_END] : 0; if ($end == 0) { $parent = $this->parent; while (!isset($parent->_[HDOM_INFO_END]) && $parent !== null) { $end -= 1; $parent = $parent->parent; } $end += $parent->_[HDOM_INFO_END]; } for ($i = $this->_[HDOM_INFO_BEGIN] + 1; $i < $end; ++$i) { $node = $this->dom->nodes[$i]; $pass = true; if ($tag === '*' && !$key) { if (in_array($node, $this->children, true)) $ret[$i] = 1; continue; } // compare tag if ($tag && $tag != $node->tag && $tag !== '*') { $pass = false; } // compare key if ($pass && $key) { if ($no_key) { if (isset($node->attr[$key])) $pass = false; } else { if (($key != "plaintext") && !isset($node->attr[$key])) $pass = false; } } // compare value if ($pass && $key && $val && $val !== '*') { // If they have told us that this is a "plaintext" search then we want the plaintext of the node - right? if ($key == "plaintext") { // $node->plaintext actually returns $node->text(); $nodeKeyValue = $node->text(); } else { // this is a normal search, we want the value of that attribute of the tag. $nodeKeyValue = $node->attr[$key]; } if (is_object($debugObject)) { $debugObject->debugLog(2, "testing node: " . $node->tag . " for attribute: " . $key . $exp . $val . " where nodes value is: " . $nodeKeyValue); } //PaperG - If lowercase is set, do a case insensitive test of the value of the selector. if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($nodeKeyValue)); } else { $check = $this->match($exp, $val, $nodeKeyValue); } if (is_object($debugObject)) { $debugObject->debugLog(2, "after match: " . ($check ? "true" : "false")); } // handle multiple class if (!$check && strcasecmp($key, 'class') === 0) { foreach (explode(' ', $node->attr[$key]) as $k) { // Without this, there were cases where leading, trailing, or double spaces lead to our comparing blanks - bad form. if (!empty($k)) { if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($k)); } else { $check = $this->match($exp, $val, $k); } if ($check) break; } } } if (!$check) $pass = false; } if ($pass) $ret[$i] = 1; unset($node); } // It's passed by reference so this is actually what this function returns. if (is_object($debugObject)) { $debugObject->debugLog(1, "EXIT - ret: ", $ret); } } protected function match($exp, $pattern, $value) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } switch ($exp) { case '=': return ($value === $pattern); case '!=': return ($value !== $pattern); case '^=': return preg_match("/^" . preg_quote($pattern, '/') . "/", $value); case '$=': return preg_match("/" . preg_quote($pattern, '/') . "$/", $value); case '*=': if ($pattern[0] == '/') { return preg_match($pattern, $value); } return preg_match("/" . $pattern . "/i", $value); } return false; } protected function parse_selector($selector_string) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // pattern of CSS selectors, modified from mootools // Paperg: Add the colon to the attrbute, so that it properly finds <tag attr:ibute="something" > like google does. // Note: if you try to look at this attribute, yo MUST use getAttribute since $dom->x:y will fail the php syntax check. // Notice the \[ starting the attbute? and the @? following? This implies that an attribute can begin with an @ sign that is not captured. // This implies that an html attribute specifier may start with an @ sign that is NOT captured by the expression. // farther study is required to determine of this should be documented or removed. // $pattern = "/([\w-:\*]*)(?:\#([\w-]+)|\.([\w-]+))?(?:\[@?(!?[\w-]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; $pattern = "/([\w\-:\*]*)(?:\#([\w\-]+)|\.([\w\-]+))?(?:\[@?(!?[\w\-:]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; preg_match_all($pattern, trim($selector_string) . ' simple_html_dom.php', $matches, PREG_SET_ORDER); if (is_object($debugObject)) { $debugObject->debugLog(2, "Matches Array: ", $matches); } $selectors = array(); $result = array(); //print_r($matches); foreach ($matches as $m) { $m[0] = trim($m[0]); if ($m[0] === '' || $m[0] === '/' || $m[0] === '//') continue; // for browser generated xpath if ($m[1] === 'tbody') continue; list($tag, $key, $val, $exp, $no_key) = array($m[1], null, null, '=', false); if (!empty($m[2])) { $key = 'id'; $val = $m[2]; } if (!empty($m[3])) { $key = 'class'; $val = $m[3]; } if (!empty($m[4])) { $key = $m[4]; } if (!empty($m[5])) { $exp = $m[5]; } if (!empty($m[6])) { $val = $m[6]; } // convert to lowercase if ($this->dom->lowercase) { $tag = strtolower($tag); $key = strtolower($key); } //elements that do NOT have the specified attribute if (isset($key[0]) && $key[0] === '!') { $key = substr($key, 1); $no_key = true; } $result[] = array($tag, $key, $val, $exp, $no_key); if (trim($m[7]) === ',') { $selectors[] = $result; $result = array(); } } if (count($result) > 0) $selectors[] = $result; return $selectors; } function __get($name) { if (isset($this->attr[$name])) { return $this->convert_text($this->attr[$name]); } switch ($name) { case 'outertext': return $this->outertext(); case 'innertext': return $this->innertext(); case 'plaintext': return $this->text(); case 'xmltext': return $this->xmltext(); default: return array_key_exists($name, $this->attr); } } function __set($name, $value) { switch ($name) { case 'outertext': return $this->_[HDOM_INFO_OUTER] = $value; case 'innertext': if (isset($this->_[HDOM_INFO_TEXT])) return $this->_[HDOM_INFO_TEXT] = $value; return $this->_[HDOM_INFO_INNER] = $value; } if (!isset($this->attr[$name])) { $this->_[HDOM_INFO_SPACE][] = array(' ', '', ''); $this->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; } $this->attr[$name] = $value; } function __isset($name) { switch ($name) { case 'outertext': return true; case 'innertext': return true; case 'plaintext': return true; } //no value attr: nowrap, checked selected... return (array_key_exists($name, $this->attr)) ? true : isset($this->attr[$name]); } function __unset($name) { if (isset($this->attr[$name])) unset($this->attr[$name]); } // PaperG - Function to convert the text from one character set to another if the two sets are not the same. function convert_text($text) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } $converted_text = $text; $sourceCharset = ""; $targetCharset = ""; if ($this->dom) { $sourceCharset = strtoupper($this->dom->_charset); $targetCharset = strtoupper($this->dom->_target_charset); } if (is_object($debugObject)) { $debugObject->debugLog(3, "source charset: " . $sourceCharset . " target charaset: " . $targetCharset); } if (!empty($sourceCharset) && !empty($targetCharset) && (strcasecmp($sourceCharset, $targetCharset) != 0)) { // Check if the reported encoding could have been incorrect and the text is actually already UTF-8 if ((strcasecmp($targetCharset, 'UTF-8') == 0) && ($this->is_utf8($text))) { $converted_text = $text; } else { $converted_text = iconv($sourceCharset, $targetCharset, $text); } } return $converted_text; } function is_utf8($string) { return (utf8_encode(utf8_decode($string)) == $string); } // camel naming conventions function getAllAttributes() { return $this->attr; } function getAttribute($name) { return $this->__get($name); } function setAttribute($name, $value) { $this->__set($name, $value); } function hasAttribute($name) { return $this->__isset($name); } function removeAttribute($name) { $this->__set($name, null); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = null) { return $this->find($name, $idx); } function parentNode() { return $this->parent(); } function childNodes($idx = -1) { return $this->children($idx); } function firstChild() { return $this->first_child(); } function lastChild() { return $this->last_child(); } function nextSibling() { return $this->next_sibling(); } function previousSibling() { return $this->prev_sibling(); } } /** * simple html dom parser * Paperg - in the find routine: allow us to specify that we want case insensitive testing of the value of the selector. * Paperg - change $size from protected to public so we can easily access it * Paperg - added ForceTagsClosed in the constructor which tells us whether we trust the html or not. Default is to NOT trust it. * * @package PlaceLocalInclude */ class simple_html_dom { public $root = null; public $nodes = array(); public $callback = null; public $lowercase = false; public $size; protected $pos; protected $doc; protected $char; protected $cursor; protected $parent; protected $noise = array(); protected $token_blank = " \t\r\n"; protected $token_equal = ' =/>'; protected $token_slash = " />\r\n\t"; protected $token_attr = ' >'; protected $_charset = ''; protected $_target_charset = ''; protected $default_br_text = ""; // use isset instead of in_array, performance boost about 30%... protected $self_closing_tags = array('img' => 1, 'br' => 1, 'input' => 1, 'meta' => 1, 'link' => 1, 'hr' => 1, 'base' => 1, 'embed' => 1, 'spacer' => 1); protected $block_tags = array('root' => 1, 'body' => 1, 'form' => 1, 'div' => 1, 'span' => 1, 'table' => 1); // Known sourceforge issue #2977341 // B tags that are not closed cause us to return everything to the end of the document. protected $optional_closing_tags = array( 'tr' => array('tr' => 1, 'td' => 1, 'th' => 1), 'th' => array('th' => 1), 'td' => array('td' => 1), 'li' => array('li' => 1), 'dt' => array('dt' => 1, 'dd' => 1), 'dd' => array('dd' => 1, 'dt' => 1), 'dl' => array('dd' => 1, 'dt' => 1), 'p' => array('p' => 1), 'nobr' => array('nobr' => 1), 'b' => array('b' => 1), ); function __construct($str = null, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { if ($str) { if (preg_match("/^http:\/\//i", $str) || is_file($str)) $this->load_file($str); else $this->load($str, $lowercase, $stripRN, $defaultBRText); } // Forcing tags to be closed implies that we don't trust the html, but it can lead to parsing errors if we SHOULD trust the html. if (!$forceTagsClosed) { $this->optional_closing_array = array(); } $this->_target_charset = $target_charset; } function __destruct() { $this->clear(); } // load html from string function load($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { global $debugObject; // prepare $this->prepare($str, $lowercase, $stripRN, $defaultBRText); // strip out comments $this->remove_noise("'<!--(.*?)-->'is"); // strip out cdata $this->remove_noise("'<!\[CDATA\[(.*?)\]\]>'is", true); // Per sourceforge http://sourceforge.net/tracker/?func=detail&aid=2949097&group_id=218559&atid=1044037 // Script tags removal now preceeds style tag removal. // strip out <script> tags $this->remove_noise("'<\s*script[^>]*[^/]>(.*?)<\s*/\s*script\s*>'is"); $this->remove_noise("'<\s*script\s*>(.*?)<\s*/\s*script\s*>'is"); // strip out <style> tags $this->remove_noise("'<\s*style[^>]*[^/]>(.*?)<\s*/\s*style\s*>'is"); $this->remove_noise("'<\s*style\s*>(.*?)<\s*/\s*style\s*>'is"); // strip out preformatted tags $this->remove_noise("'<\s*(?:code)[^>]*>(.*?)<\s*/\s*(?:code)\s*>'is"); // strip out server side scripts $this->remove_noise("'(<\?)(.*?)(\?>)'s", true); // strip smarty scripts $this->remove_noise("'(\{\w)(.*?)(\})'s", true); // parsing while ($this->parse()) ; // end $this->root->_[HDOM_INFO_END] = $this->cursor; $this->parse_charset(); } // load html from file function load_file() { $args = func_get_args(); $this->load(call_user_func_array('file_get_contents', $args), true); // Per the simple_html_dom repositiry this is a planned upgrade to the codebase. // Throw an error if we can't properly load the dom. if (($error = error_get_last()) !== null) { $this->clear(); return false; } } // set callback function function set_callback($function_name) { $this->callback = $function_name; } // remove callback function function remove_callback() { $this->callback = null; } // save dom as string function save($filepath = '') { $ret = $this->root->innertext(); if ($filepath !== '') file_put_contents($filepath, $ret, LOCK_EX); return $ret; } // find dom node by css selector // Paperg - allow us to specify that we want case insensitive testing of the value of the selector. function find($selector, $idx = null, $lowercase = false) { return $this->root->find($selector, $idx, $lowercase); } // clean up memory due to php5 circular references memory leak... function clear() { foreach ($this->nodes as $n) { $n->clear(); $n = null; } // This add next line is documented in the sourceforge repository. 2977248 as a fix for ongoing memory leaks that occur even with the use of clear. if (isset($this->children)) foreach ($this->children as $n) { $n->clear(); $n = null; } if (isset($this->parent)) { $this->parent->clear(); unset($this->parent); } if (isset($this->root)) { $this->root->clear(); unset($this->root); } unset($this->doc); unset($this->noise); } function dump($show_attr = true) { $this->root->dump($show_attr); } // prepare HTML data and init everything protected function prepare($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $this->clear(); // set the length of content before we do anything to it. $this->size = strlen($str); //before we save the string as the doc... strip out the \r \n's if we are told to. if ($stripRN) { $str = str_replace("\r", " ", $str); $str = str_replace("\n", " ", $str); } $this->doc = $str; $this->pos = 0; $this->cursor = 1; $this->noise = array(); $this->nodes = array(); $this->lowercase = $lowercase; $this->default_br_text = $defaultBRText; $this->root = new simple_html_dom_node($this); $this->root->tag = 'root'; $this->root->_[HDOM_INFO_BEGIN] = -1; $this->root->nodetype = HDOM_TYPE_ROOT; $this->parent = $this->root; if ($this->size > 0) $this->char = $this->doc[0]; } // parse html content protected function parse() { if (($s = $this->copy_until_char('<')) === '') return $this->read_tag(); // text $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = $s; $this->link_nodes($node, false); return true; } // PAPERG - dkchou - added this to try to identify the character set of the page we have just parsed so we know better how to spit it out later. // NOTE: IF you provide a routine called get_last_retrieve_url_contents_content_type which returns the CURLINFO_CONTENT_TYPE fromt he last curl_exec // (or the content_type header fromt eh last transfer), we will parse THAT, and if a charset is specified, we will use it over any other mechanism. protected function parse_charset() { global $debugObject; $charset = null; if (function_exists('get_last_retrieve_url_contents_content_type')) { $contentTypeHeader = get_last_retrieve_url_contents_content_type(); $success = preg_match('/charset=(.+)/', $contentTypeHeader, $matches); if ($success) { $charset = $matches[1]; if (is_object($debugObject)) { $debugObject->debugLog(2, 'header content-type found charset of: ' . $charset); } } } if (empty($charset)) { $el = $this->root->find('meta[http-equiv=Content-Type]', 0); if (!empty($el)) { $fullvalue = $el->content; if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag found' . $fullValue); } if (!empty($fullvalue)) { $success = preg_match('/charset=(.+)/', $fullvalue, $matches); if ($success) { $charset = $matches[1]; } else { // If there is a meta tag, and they don't specify the character set, research says that it's typically ISO-8859-1 if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag couldn\'t be parsed. using iso-8859 default.'); } $charset = 'ISO-8859-1'; } } } } // If we couldn't find a charset above, then lets try to detect one based on the text we got... if (empty($charset)) { // Have php try to detect the encoding from the text given to us. $charset = mb_detect_encoding($this->root->plaintext . "ascii", $encoding_list = array("UTF-8", "CP1252")); if (is_object($debugObject)) { $debugObject->debugLog(2, 'mb_detect found: ' . $charset); } // and if this doesn't work... then we need to just wrongheadedly assume it's UTF-8 so that we can move on - cause this will usually give us most of what we need... if ($charset === false) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'since mb_detect failed - using default of utf-8'); } $charset = 'UTF-8'; } } // Since CP1252 is a superset, if we get one of it's subsets, we want it instead. if ((strtolower($charset) == strtolower('ISO-8859-1')) || (strtolower($charset) == strtolower('Latin1')) || (strtolower($charset) == strtolower('Latin-1'))) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'replacing ' . $charset . ' with CP1252 as its a superset'); } $charset = 'CP1252'; } if (is_object($debugObject)) { $debugObject->debugLog(1, 'EXIT - ' . $charset); } return $this->_charset = $charset; } // read tag info protected function read_tag() { if ($this->char !== '<') { $this->root->_[HDOM_INFO_END] = $this->cursor; return false; } $begin_tag_pos = $this->pos; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // end tag if ($this->char === '/') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // This represetns the change in the simple_html_dom trunk from revision 180 to 181. // $this->skip($this->token_blank_t); $this->skip($this->token_blank); $tag = $this->copy_until_char('>'); // skip attributes in end tag if (($pos = strpos($tag, ' ')) !== false) $tag = substr($tag, 0, $pos); $parent_lower = strtolower($this->parent->tag); $tag_lower = strtolower($tag); if ($parent_lower !== $tag_lower) { if (isset($this->optional_closing_tags[$parent_lower]) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent if ($this->parent->parent) $this->parent = $this->parent->parent; $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && strtolower($this->parent->parent->tag) === $tag_lower) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } else return $this->as_text_node($tag); } $this->parent->_[HDOM_INFO_END] = $this->cursor; if ($this->parent->parent) $this->parent = $this->parent->parent; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } $node = new simple_html_dom_node($this); $node->_[HDOM_INFO_BEGIN] = $this->cursor; ++$this->cursor; $tag = $this->copy_until($this->token_slash); $node->tag_start = $begin_tag_pos; // doctype, cdata & comments... if (isset($tag[0]) && $tag[0] === '!') { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until_char('>'); if (isset($tag[2]) && $tag[1] === '-' && $tag[2] === '-') { $node->nodetype = HDOM_TYPE_COMMENT; $node->tag = 'comment'; } else { $node->nodetype = HDOM_TYPE_UNKNOWN; $node->tag = 'unknown'; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, true); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // text if ($pos = strpos($tag, '<') !== false) { $tag = '<' . substr($tag, 0, -1); $node->_[HDOM_INFO_TEXT] = $tag; $this->link_nodes($node, false); $this->char = $this->doc[--$this->pos]; // prev return true; } if (!preg_match("/^[\w\-:]+$/", $tag)) { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until('<>'); if ($this->char === '<') { $this->link_nodes($node, false); return true; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // begin tag $node->nodetype = HDOM_TYPE_ELEMENT; $tag_lower = strtolower($tag); $node->tag = ($this->lowercase) ? $tag_lower : $tag; // handle optional closing tags if (isset($this->optional_closing_tags[$tag_lower])) { while (isset($this->optional_closing_tags[$tag_lower][strtolower($this->parent->tag)])) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } $node->parent = $this->parent; } $guard = 0; // prevent infinity loop $space = array($this->copy_skip($this->token_blank), '', ''); // attributes do { if ($this->char !== null && $space[0] === '') break; $name = $this->copy_until($this->token_equal); if ($guard === $this->pos) { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next continue; } $guard = $this->pos; // handle endless '<' if ($this->pos >= $this->size - 1 && $this->char !== '>') { $node->nodetype = HDOM_TYPE_TEXT; $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = '<' . $tag . $space[0] . $name; $node->tag = 'text'; $this->link_nodes($node, false); return true; } // handle mismatch '<' if ($this->doc[$this->pos - 1] == '<') { $node->nodetype = HDOM_TYPE_TEXT; $node->tag = 'text'; $node->attr = array(); $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = substr($this->doc, $begin_tag_pos, $this->pos - $begin_tag_pos - 1); $this->pos -= 2; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->link_nodes($node, false); return true; } if ($name !== '/' && $name !== '') { $space[1] = $this->copy_skip($this->token_blank); $name = $this->restore_noise($name); if ($this->lowercase) $name = strtolower($name); if ($this->char === '=') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->parse_attr($node, $name, $space); } else { //no value attr: nowrap, checked selected... $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = true; if ($this->char != '>') $this->char = $this->doc[--$this->pos]; // prev } $node->_[HDOM_INFO_SPACE][] = $space; $space = array($this->copy_skip($this->token_blank), '', ''); } else break; } while ($this->char !== '>' && $this->char !== '/'); $this->link_nodes($node, true); $node->_[HDOM_INFO_ENDSPACE] = $space[0]; // check self closing if ($this->copy_until_char_escape('>') === '/') { $node->_[HDOM_INFO_ENDSPACE] .= '/'; $node->_[HDOM_INFO_END] = 0; } else { // reset parent if (!isset($this->self_closing_tags[strtolower($node->tag)])) $this->parent = $node; } $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // If it's a BR tag, we need to set it's text to the default text. // This way when we see it in plaintext, we can generate formatting that the user wants. if ($node->tag == "br") { $node->_[HDOM_INFO_INNER] = $this->default_br_text; } return true; } // parse attributes protected function parse_attr($node, $name, &$space) { // Per sourceforge: http://sourceforge.net/tracker/?func=detail&aid=3061408&group_id=218559&atid=1044037 // If the attribute is already defined inside a tag, only pay atetntion to the first one as opposed to the last one. if (isset($node->attr[$name])) { return; } $space[2] = $this->copy_skip($this->token_blank); switch ($this->char) { case '"': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('"')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; case '\'': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_SINGLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('\'')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; default: $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = $this->restore_noise($this->copy_until($this->token_attr)); } // PaperG: Attributes should not have \r or \n in them, that counts as html whitespace. $node->attr[$name] = str_replace("\r", "", $node->attr[$name]); $node->attr[$name] = str_replace("\n", "", $node->attr[$name]); // PaperG: If this is a "class" selector, lets get rid of the preceeding and trailing space since some people leave it in the multi class case. if ($name == "class") { $node->attr[$name] = trim($node->attr[$name]); } } // link node's parent protected function link_nodes(&$node, $is_child) { $node->parent = $this->parent; $this->parent->nodes[] = $node; if ($is_child) $this->parent->children[] = $node; } // as a text node protected function as_text_node($tag) { $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = '</' . $tag . '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } protected function skip($chars) { $this->pos += strspn($this->doc, $chars, $this->pos); $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next } protected function copy_skip($chars) { $pos = $this->pos; $len = strspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next if ($len === 0) return ''; return substr($this->doc, $pos, $len); } protected function copy_until($chars) { $pos = $this->pos; $len = strcspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return substr($this->doc, $pos, $len); } protected function copy_until_char($char) { if ($this->char === null) return ''; if (($pos = strpos($this->doc, $char, $this->pos)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } protected function copy_until_char_escape($char) { if ($this->char === null) return ''; $start = $this->pos; while (1) { if (($pos = strpos($this->doc, $char, $start)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; if ($this->doc[$pos - 1] === '\\') { $start = $pos + 1; continue; } $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } } // remove noise from html content protected function remove_noise($pattern, $remove_tag = false) { $count = preg_match_all($pattern, $this->doc, $matches, PREG_SET_ORDER | PREG_OFFSET_CAPTURE); for ($i = $count - 1; $i > -1; --$i) { $key = '___noise___' . sprintf('% 3d', count($this->noise) + 100); $idx = ($remove_tag) ? 0 : 1; $this->noise[$key] = $matches[$i][$idx][0]; $this->doc = substr_replace($this->doc, $key, $matches[$i][$idx][1], strlen($matches[$i][$idx][0])); } // reset the length of content $this->size = strlen($this->doc); if ($this->size > 0) $this->char = $this->doc[0]; } // restore noise to html content function restore_noise($text) { while (($pos = strpos($text, '___noise___')) !== false) { $key = '___noise___' . $text[$pos + 11] . $text[$pos + 12] . $text[$pos + 13]; if (isset($this->noise[$key])) // $text = simple_html_dom . phpsubstr($text, 0, $pos) . $this->noise[$key] . substr($text, $pos + 14); $text = substr($text, 0, $pos).$this->noise[$key].substr($text, $pos+14); } return $text; } function __toString() { return $this->root->innertext(); } function __get($name) { switch ($name) { case 'outertext': return $this->root->innertext(); case 'innertext': return $this->root->innertext(); case 'plaintext': return $this->root->text(); case 'charset': return $this->_charset; case 'target_charset': return $this->_target_charset; } } // camel naming conventions function childNodes($idx = -1) { return $this->root->childNodes($idx); } function firstChild() { return $this->root->first_child(); } function lastChild() { return $this->root->last_child(); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = -1) { return $this->find($name, $idx); } function loadFile() { $args = func_get_args(); $this->load_file($args); } } ?> 引用1.php-simple-html-dom-parser for PHP7.3 +:https://github.com/sunra/php-simple-html-dom-parser/issues/75 -
Laravel Blade分页模板 自带的有点丑,整个模板换掉模板放在/resources/views/vendor/pagination/bootstrap-3.blade.php<nav aria-label="Page navigation example"> <ul class="stui-page text-center clearfix"> <li><a href="{{ $paginator->url(1) }}">首页</a></li> <li><a href="{{ $paginator->previousPageUrl() }}">上一页</a></li> @if($paginator->onFirstPage()) <li class="hidden-xs active"><a href="{{ $paginator->url(1) }}">1</a></li> @for($i = 2;$i <= (($paginator->lastPage() > 5) ? 5 : $paginator->lastPage());$i++) <!-- 判断当前数据总数是否能够渲染当前页面 --> <li class="hidden-xs"><a href="{{ $paginator->appends(request()->query())->url($i) }}">{{ $i }}</a></li> @endfor @elseif(!$paginator->hasMorePages()) @for($i = $paginator->lastPage() - 3;$i <= $paginator->lastPage();$i++) <li class="hidden-xs"><a href="{{ $paginator->url($i) }}">{{ $i }}</a></li> @endfor <li class="hidden-xs active"><a href="{{ $paginator->url($paginator->lastPage()) }}">{{ $paginator->lastPage() }}</a></li> @else <!-- 分页功能显示中间部分 --> @for($i = $paginator->currentPage() - 2; $i <= $paginator->currentPage() + 2; $i++) @if($i > 0) @if($i == $paginator->currentPage()) <li class="hidden-xs active"><a href="{{ $paginator->url($i) }}">{{ $i }}</a></li> @else <li class="hidden-xs"><a href="{{ $paginator->url($i) }}">{{ $i }}</a></li> @endif @endif @endfor @endif <li class="active"><span class="num">{{ $paginator->currentPage() }}/{{ $paginator->lastPage() }}</span></li> <li><a href="{{ $paginator->nextPageUrl() }}">下一页</a></li> <li><a href="{{ $paginator->url($paginator->lastPage()) }}">尾页</a></li> </ul> </nav>样式:.stui-page li { display: inline-block; margin-left: 10px; } ul, ol, li, dt, dd { margin: 0; padding: 0; list-style: none; } .stui-page li .num, .stui-page li a { display: inline-block; padding: 5px 15px; border-radius: 4px; background-color: #fff; border: 1px solid #eee; } .stui-page li.active a, .stui-page li.disabled a { background-color: #f2990d; border: 1px solid #f2990d; color: #fff; } a, h1, h2, h3, h4, h5, h6 { color: #333333; } a, button { text-decoration: none; outline: none; -webkit-tap-highlight-color: rgba(0,0,0,0); }有些class是Boostrap3的在其他文件中使用时,如下@component('vendor.pagination.bootstrap-3', ['paginator' => $videoList]) @endcomponent
-
Homestead中PHP版本问题 Homestead中PHP版本问题1.项目运行时PHP版本1.1 查看Homestead中可用的PHP版本ll /etc/php可用版本是有许多的默认Homestead环境使用的是最新的PHP 8.1.8:1.2 切换项目使用版本在Homestead.yaml文件中进行配置:... sites: - map: yxq.test to: /home/vagrant/yxq-admin/public php: "7.3" ...然后重载一下虚拟机vagrant reload --provision2.Composer使用版本项目是从Github上Clone下来的,在composer update时报了一堆错误看了一下已上线的环境使用的PHP 7.3当我直接使用composer update时,默认会调用环境变量中的PHP 8.1查看一下PHP的环境变量设置whereis php发现各个版本都是有的,只是调用时候要加上版本号所以只能放弃全局的Composer,单独在项目中下载一个composer.pharphp7.3 composer.phar update之后的所有对artisan的操作,都要使用php7.3 artisan ...的方式了,避免因为版本不正确而导致错误发生。PS:可以直接更换环境变量,一劳永逸,我主用的还是最新版 所以没必要换了。# 安装完新项目的依赖后,要拷贝一下.env vagrant@homestead:~/yxq-admin$ cp .env.example .env # 生成key vagrant@homestead:~/yxq-admin$ php7.3 artisan key:generate Application key set successfully.接下来数据库迁移修改一下.envDB_DATABASE=yxq DB_USERNAME=homestead DB_PASSWORD=secret执行迁移php7.3 artisan migrate3.Vagrant常用命令序号命令解释1vagrant up启动虚拟机2vagrant ssh登录虚拟机 通过 exit 退出3vagrant status查看虚拟机状态4vagrant halt关机5vagrant destroy删除虚拟机6vagrant reload --provision修改配置文件后重载引用1.Laravel Homestead:https://laravel.com/docs/9.x/homestead#main-content2.composer.phar Download: https://getcomposer.org/download/3.多版本php环境,指定composer 使用的php版本: https://segmentfault.com/q/10100000126268834.homestead 添加新站点:https://www.cnblogs.com/cjjjj/p/9420844.html
-
How to set up debugging with PhpStorm and Homestead 20-xdebug.inizend_extension=xdebug.so xdebug.mode = debug xdebug.discover_client_host = false xdebug.client_host = 10.0.2.2 xdebug.client_port = 9000 xdebug.max_nesting_level = 512 xdebug.start_with_request = trigger xdebug.idekey = PHPSTORM引用1.How to set up debugging with PhpStorm and Homestead:https://dev.to/daniel_werner/how-to-set-up-debugging-with-phpstorm-and-homestead-484g2.How to setup Xdebug with PhpStorm and Laravel Homestead:https://www.youtube.com/watch?v=F7PKs_U4mQg&t=351s&ab_channel=JeezyCarry
-
-
通过Fiddler抓包调试PHP内Guzzle网络请求 场景最近在做设计素材网解析下载,后台框架使用Laravel网络请求框架使用HTTP ClientLaravel provides an expressive, minimal API around the Guzzle HTTP client, allowing you to quickly make outgoing HTTP requests to communicate with other web applications. Laravel's wrapper around Guzzle is focused on its most common use cases and a wonderful developer experience.一、Fiddler配置HTTP 抓包Fiddler 主菜单 -> Tools -> Fiddler Options-> Connections-> 选中 Allowremote computers to connect装有 fiddler 的机器,找出能远程访问的 IP,一般局域网内也就是本机 IP。被抓包调试的设备在网络代理那里启用代理 -> 代理 IP 就是上面说的 IP-> 端口号默认为 8888 (可以在 fiddler 中 Connections 标签页修改)这样就 OK 了。HTTPS 抓包Fiddler 主菜单 -> Tool->Fiddler Options->HTTPS -> 选中 decrypt https traffic 和 ignore server certificate errors会提示你安装证书,必要要安装。然后同 HTTP 抓包一样操作二、代码配置代理$response = Http::withCookies(cookieStrToArray($cookie->content), 'nipic.cn') ->withOptions( [ 'proxy' => '127.0.0.1:8888', // 端口为Fiddler中配置的端口 'verify' => false, // 禁用证书验证 ]) ->withHeaders([ 'Accept' => 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Encoding' => 'gzip, deflate, br', ]) ->withUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36') ->get("https://down.nipic.cn/download?id=$resourceId")->body();再次请求可以看到Fiddler拦截到了请求。三、使用Telescope需要安装一下对应的依赖# You may use the Composer package manager to install Telescope into your Laravel project: composer require laravel/telescope --dev # After installing Telescope, publish its assets using the telescope:install Artisan command. After installing Telescope, you should also run the migrate command in order to create the tables needed to store Telescope's data: php artisan telescope:install php artisan migrate只有使用HTTP Client才会被记录,而且请求和响应的记录信息不太全,所以使用Fiddler还是更好的选择。引用1.Fiddler 抓包调试 : https://www.chengxiaobai.cn/skills/fiddler-capture-debugging.html2.laravel中使用Guzzle 报 unable to get local issuer certificate错误信息:https://blog.csdn.net/worldmakewayfordream/article/details/1143020203.Guzzle 6 请求选项 :https://guzzle-cn.readthedocs.io/zh_CN/latest/request-options.html4.如何获取php向其它网站发起了什么请求,有什么办法?: https://learnku.com/laravel/t/673455.HTTP Client : https://laravel.com/docs/9.x/http-client6.Laravel Telescope : https://laravel.com/docs/9.x/telescope
-
Laravel Breeze(vue) and Homestead - npm run dev and HMR not working Laravel Breeze(vue) and Homestead - npm run dev and HMR not workingQuestionI followed the instructions from the documentation:Homestead: https://laravel.com/docs/9.x/homestead#installation-and-setupBreeze with Vue and inertia: https://laravel.com/docs/9.x/starter-kits#breeze-and-inertiaWhen I run npm run build everything works fine. I can visit my new app over http://homestead.test/. When I try to use the dev server with hot reload npm run dev, the debug console in my browser (host) tells:GET http://127.0.0.1:5173/@vite/client net::ERR_CONNECTION_REFUSED GET http://127.0.0.1:5173/resources/js/app.js net::ERR_CONNECTION_REFUSEDI already tried to change my package.json file to from "dev": "vite", to "dev": "vite --host homestead.test", but this only results in the errorsGET http://homestead.test:5173/@vite/client net::ERR_CONNECTION_REFUSED GET http://homestead.test:5173/resources/js/app.js net::ERR_CONNECTION_REFUSEDIn app.blade.php the scripts are imported with @<!DOCTYPE html> <html lang="{{ str_replace('_', '-', app()->getLocale()) }}"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title inertia>{{ config('app.name', 'Laravel') }}</title> <!-- Fonts --> <link rel="stylesheet" href="https://fonts.bunny.net/css2?family=Nunito:wght@400;600;700&display=swap"> <!-- Scripts --> @routes @vite('resources/js/app.js') @inertiaHead </head> <body class="font-sans antialiased"> @inertia </body> </html>@routes seems to be a part of the Laravel Ziggy package. No error from this side.But the @vite('resources/js/app.js') and @inertiaHead are throwing errors. These directives link to a wrong destination.How to solve this?AnswerI've found the solution. Add the server part in your vite.config.js. And add the app.css to the inputsimport { defineConfig } from 'vite'; import laravel from 'laravel-vite-plugin'; import vue from '@vitejs/plugin-vue'; export default defineConfig({ server: { hmr: { host: "192.168.56.56", }, host: "192.168.56.56", watch: { usePolling: true, }, }, plugins: [ laravel({ input: ['resources/js/app.js', 'resources/css/app.css'], refresh: true, }), vue({ template: { transformAssetUrls: { base: null, includeAbsolute: false, }, }, }), ], });Quote1.Laravel Breeze (vue) and Homestead - npm run dev and HMR not working : https://stackoverflow.com/questions/73506437/laravel-breeze-vue-and-homestead-npm-run-dev-and-hmr-not-working
-
初探Laravel Starters Kits的Breeze&Vue 简介Breeze 是官方推荐的起手套装,内建有登入、注册、忘记密码等常用的用户功能,另外可以选择使用 Vue 或者 React 来建立SPA单页页面。首先,Breeze 适用于专门初始化的工具,如果项目已经开发到一半的话可能会有冲突,所以不适用。最好建立一个初始化的工程。创建工程1.创建项目如果是8或更低的版本中前端资源打包使用了mix执行npm install 和 npm run dev后,页面无法正常解析,属于是坑了解决方案:https://learnku.com/laravel/t/69192所以避免踩坑直接采用了最新版的v 9.3.3的Laravelcomposer create-project laravel/laravel=9.*.* --prefer-dist projectName2.安装breezecomposer require laravel/breeze --dev官方文档:https://laravel.com/docs/9.x/starter-kits#laravel-breeze-installation3.安装breeze & React/Vuephp artisan breeze:install vue # Or... php artisan breeze:install react php artisan migrate npm install npm run dev4.查看效果需要跑两个控制台图中左侧运行服务端:php artisan serve右侧运行前端:npm run dev访问http://127.0.0.1:8000查看!自带了登录、注册功能,单页应用全程无刷新,nice!架构分析探索一下 Laravel 是如何实现这些的1.浅析路由和组件首先看到 routes/auth.php,这里定义了使用者登录之前的页面路由与 API,包含注册、登入登出、忘记密码等。以 Get/login 为例,由 AuthenticatedSessionController 的 create 方法处理请求后回传登录页面。 在这之前加上了 guest 这个 middleware,如果请求带有已登录的状态,则不回传页面而直接跳到首页。Route::middleware('guest')->group(function () { // ... Route::get('login', [AuthenticatedSessionController::class, 'create']) ->name('login'); // ... });看看 AuthenticatedSessionController 的 create方法做了什么/** * Display the login view. * * @return \Inertia\Response */ public function create() { return Inertia::render('Auth/Login', //resources\js\Pages\Auth\Login.vue 页面组件 // 页面组件的Props参数 [ 'canResetPassword' => Route::has('password.request'), 'status' => session('status'), ]); }再看一下对应的Vue组件<script> defineProps({ canResetPassword: Boolean, status: String, }); </script> <template> ... <div v-if="status" class="mb-4 font-medium text-sm text-green-600"> {{ status }} </div> ... ... <Link v-if="canResetPassword" :href="route('password.request')" class="underline text-sm text-gray-600 hover:text-gray-900"> Forgot your password? </Link> ... </template>瞬间明白,php中可以直接返回信息回传给Inertia.js进行渲染页面,组件中进行defineProps声明后即可使用。2.Inertia原理這邊簡單說下 Inertia.js 的運作方式,最初連上網站的時候,會回傳一個帶有 Inertia 功能的全頁應用,而這個應用裡所有的 link 都會經過 Inertia 的處理,當點擊 link 時並不會直接跳轉網址而是變成發送一個 XHR 到 Laravel ,並經由 API 回傳 Inertia 渲染的畫面元件,進行畫面的更新。而說是 API 渲染元件其實有點不太準確,收到請求後 Inertia Render 會將 Vue/React 元件轉換成 JSON 並回傳(不是 Html),再經由前端的 Inertia 解析後重新渲染部分的畫面,達到類前端 App 的效果,所以實際的渲染還是發生在前端,API 只是提供資料。另外這個方法前端是沒有路由器的,Laravel 伺服器提供畫面的路由器替代了這部分。本段来自:https://ithelp.ithome.com.tw/articles/10267034?sc=iThelpR3.Vue目录结构进一步学习留个官方文档入口: https://laravel.com/docs/9.x/vite引用1.Laravel8.5使用套件laravel breeze ,所有页面版式都未正确加载:https://learnku.com/laravel/t/691922.Laravel Starter kits :https://laravel.com/docs/9.x/starter-kits#introduction3.使用 Breeze 建立基礎專案框架:https://ithelp.ithome.com.tw/articles/10267034?sc=iThelpR4.Migrating from Laravel Mix to Vite:https://github.com/laravel/vite-plugin/blob/main/UPGRADE.md#migrating-from-laravel-mix-to-vite5.Bundling Assets (Vite):https://laravel.com/docs/9.x/vite