



前言
公司最近的业务,继上文:https://lisok.cn/python/552.html
cmd命令的使用有点麻烦,于是学习了一下PyQt5画了一个GUI

实现
有几个点需要提一下
这里的日志输出是给logging添加了拦截器
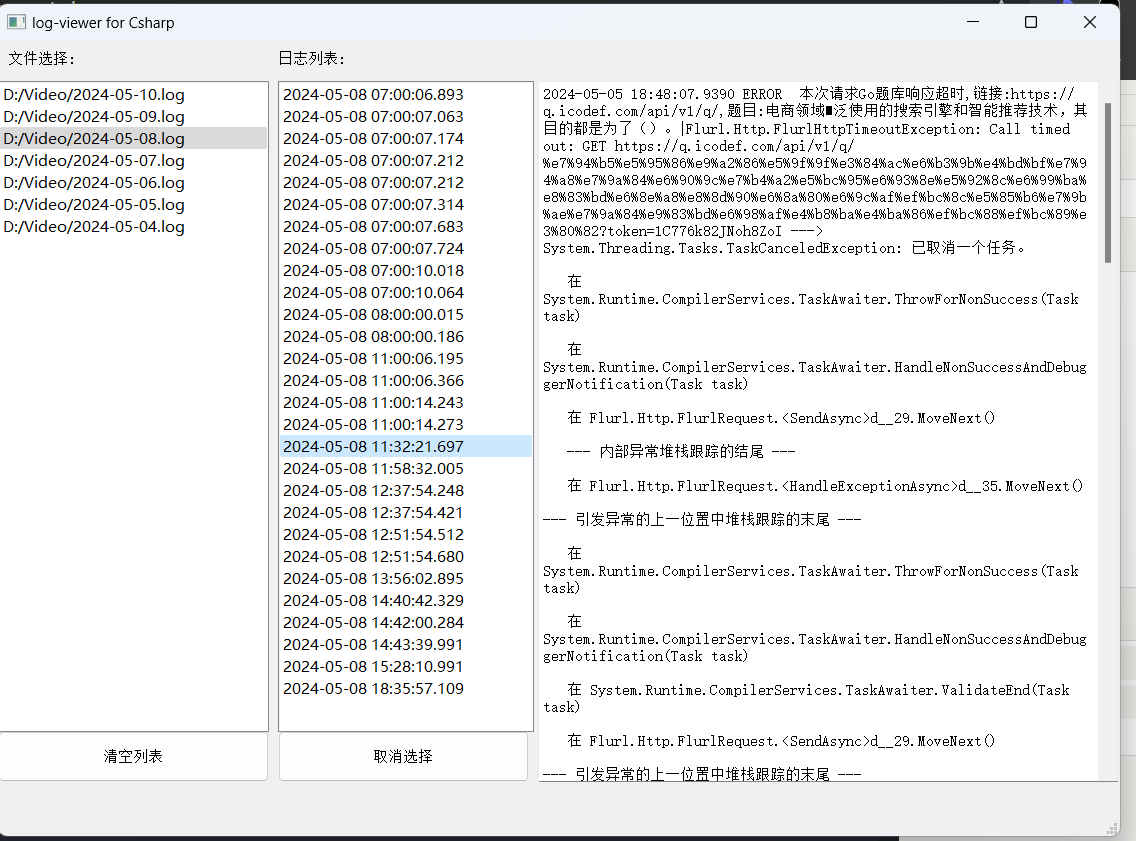
日志内容分成两部分

如图,其中store记录的是自己代码中打印的,scrapy.utils.log是scrapy内部记录的一些日志
统一添加一个handler处理 回调显示在界面上。
store.py
from ui.mainwindow import signal
class MyCustomHandler(logging.Handler):
def __init__(self, signals):
super(MyCustomHandler, self).__init__()
self.signals = signals
def emit(self, record):
log_message = self.format(record)
# 发送消息到 PyQt 界面
self.signals.log_signal.emit(log_message)
class StoreSpider(scrapy.Spider):
name = "store"
allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com']
start_urls = ["https://sale-pb.sankuai.com/apigw/api/poi/ownership/poi-not-cooperated"]
baseinfo_url = 'https://crm.sankuai.com/poi/sales/report/baseinfo?shopId={}'
pageSize = 60
pageNum = 1
startCategoryId = 0
startRequest = True
infoHeaders = {"Content-Type": "application/json; charset=UTF-8"}
custom_settings = {
'LOG_LEVEL': 'INFO',
'LOG_FILE': 'sankuai-cus.log',
}
def __init__(self, *args, **kwargs):
log_names = ['store', 'scrapy.utils.log', 'scrapy.extensions.logstats']
# 'scrapy.addons', 'scrapy.extensions.telnet', 'scrapy.middleware',
# 'scrapy.crawler', 'scrapy.core.engine',
for log_name in log_names:
logging.getLogger(log_name).addHandler(MyCustomHandler(signal))
super().__init__(*args, **kwargs)
# 设置Cookie
self.cookies = kwargs.get('cookies', [])
self.crawl_cities_ids = kwargs.get('crawl_cities_ids', [])
# ....mainwindow.py
from PyQt5.QtCore import QThread, pyqtSignal, QObject
from .ui_main_window.ui_mainwindow import Ui_MainWindow
cities = []
class MySignal(QObject):
log_signal = pyqtSignal(str)
signal = MySignal()
cookies = []
crawl_cities_ids = []
# ...其他的代码都很常规,打个包记录一下
引用
1.python scrapy框架 日志文件:https://blog.csdn.net/weixin_45459224/article/details/100142537
2.[Python自学] PyQT5-子线程更新UI数据、信号槽自动绑定、lambda传参、partial传参、覆盖槽函数:https://www.cnblogs.com/leokale-zz/p/13131953.html
3.[ PyQt入门教程 ] PyQt5中多线程模块QThread使用方法:https://www.cnblogs.com/linyfeng/p/12239856.html
4.Scrapy Logging:https://docs.scrapy.org/en/latest/topics/logging.html#logging-configuration
5.在线程中启动scrapy以及多次启动scrapy报错的解决方案(ERROR:root:signal only works in main thread):https://blog.csdn.net/Pual_wang/article/details/106466017


评论 (0)